Hello,
I am building an image classifier for 10 categories. I decided to use VGG16 architecture. My model however is not improving at all, could I please get some help.
This is my neural network.
class DeepNeuralNetwork(nn.Module):
def __init__(self, in_size, out_size, hidden_size):
super(DeepNeuralNetwork, self).__init__()
self.in_size = in_size
self.out_size = out_size
self.hidden_size = hidden_size
self.loss_tracker = []
self.accuracy_loss_tracker = []
self.accuracy_tracker = []
self.network = nn.Sequential(
# 1st block
nn.Conv2d(self.in_size, self.hidden_size, kernel_size=(3,3), stride=(1,1), padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(self.hidden_size, self.hidden_size, kernel_size=(3,3), stride=(1,1), padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=(2,2), stride=(2,2)),
nn.BatchNorm2d(self.hidden_size),
# After 1st block: 64 x 112 x 112
# 2nd block
nn.Conv2d(self.hidden_size, self.hidden_size*2, kernel_size=(3,3), stride=(1,1), padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(self.hidden_size*2, self.hidden_size*2, kernel_size=(3,3), stride=(1,1), padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=(2,2), stride=(2,2)),
nn.BatchNorm2d(self.hidden_size*2),
# After 2nd block: 128 x 56 x 56
# 3rd block
nn.Conv2d(self.hidden_size*2, self.hidden_size*4, kernel_size=(3,3), stride=(1,1), padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(self.hidden_size*4, self.hidden_size*4, kernel_size=(3,3), stride=(1,1), padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(self.hidden_size*4, self.hidden_size*4, kernel_size=(3,3), stride=(1,1), padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=(2,2), stride=(2,2)),
nn.BatchNorm2d(self.hidden_size*4),
# After 3rd block: 256 x 28 x 28
# 4th block
nn.Conv2d(self.hidden_size*4, self.hidden_size*8, kernel_size=(3,3), stride=(1,1), padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(self.hidden_size*8, self.hidden_size*8, kernel_size=(3,3), stride=(1,1), padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(self.hidden_size*8, self.hidden_size*8, kernel_size=(3,3), stride=(1,1), padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=(2,2), stride=(2,2)),
nn.BatchNorm2d(self.hidden_size*8),
# After 4th block: 512 x 14 x 14
# 5th block
nn.Conv2d(self.hidden_size*8, self.hidden_size*8, kernel_size=(3,3), stride=(1,1), padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(self.hidden_size*8, self.hidden_size*8, kernel_size=(3,3), stride=(1,1), padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(self.hidden_size*8, self.hidden_size*8, kernel_size=(3,3), stride=(1,1), padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=(2,2), stride=(2,2)),
nn.BatchNorm2d(self.hidden_size*8),
# After 5th block: 512 x 7 x 7
nn.Flatten(),
nn.Linear(self.hidden_size*8*7*7, 5000),
nn.ReLU(inplace=True),
nn.BatchNorm1d(5000),
nn.Linear(5000, 1000),
nn.ReLU(inplace=True),
nn.Linear(1000, self.out_size),
nn.Softmax(dim=1)
)
self.optimizer = torch.optim.Adam(self.parameters(), lr=0.001)
self.criterion = nn.CrossEntropyLoss()
def forward(self, x):
return self.network(x)
def train_phase(self, train_dl, validation_dl, epochs):
for epoch in tqdm(range(epochs)):
self.train()
train_epoch_loss = []
for batch in train_dl:
self.optimizer.zero_grad()
imgs, labels = batch
output = self(imgs)
loss = self.criterion(output, labels)
train_epoch_loss.append(loss.detach())
loss.backward()
self.optimizer.step()
accuracy_loss, accuracy = self.validation_phase(validation_dl)
training_loss = torch.stack(train_epoch_loss).mean().item()
self.loss_tracker.append(training_loss)
self.accuracy_loss_tracker.append(accuracy_loss)
self.accuracy_tracker.append(accuracy)
tqdm.write("Epoch {}, Loss: {} Acc_Loss: {} Acc: {}".format(epoch, training_loss, accuracy_loss, accuracy))
self.save_model()
def validation_phase(self, validation_dl):
self.eval()
accuracy_epoch_loss = []
cur_accuracy = []
with torch.no_grad():
for batch in validation_dl:
imgs, labels = batch
output = self(imgs)
loss = self.criterion(output, labels)
accuracy_epoch_loss.append(loss.detach())
accuracy = self.accuracy(output, labels)
cur_accuracy.append(accuracy)
return torch.stack(accuracy_epoch_loss).mean().item(), torch.stack(cur_accuracy).mean().item()
def accuracy(self, test_inputs, test_labels):
_, predictions = torch.max(test_inputs, dim=1)
return torch.tensor(torch.sum(predictions == test_labels).item() / len(predictions))
def save_model(self):
torch.save(self.state_dict(), 'model.pth')
def load_model(self, modelPath):
self.load_state_dict(torch.load('model.pth'))
I am running it on 1k image of each category. Batch size of 32 and num_workers of 3.
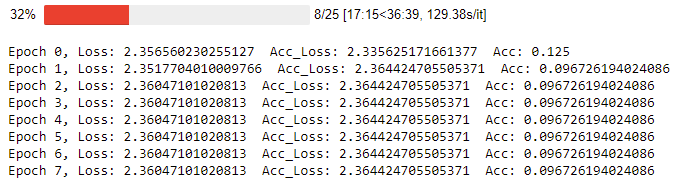
My lose and accuracy is always within this range.