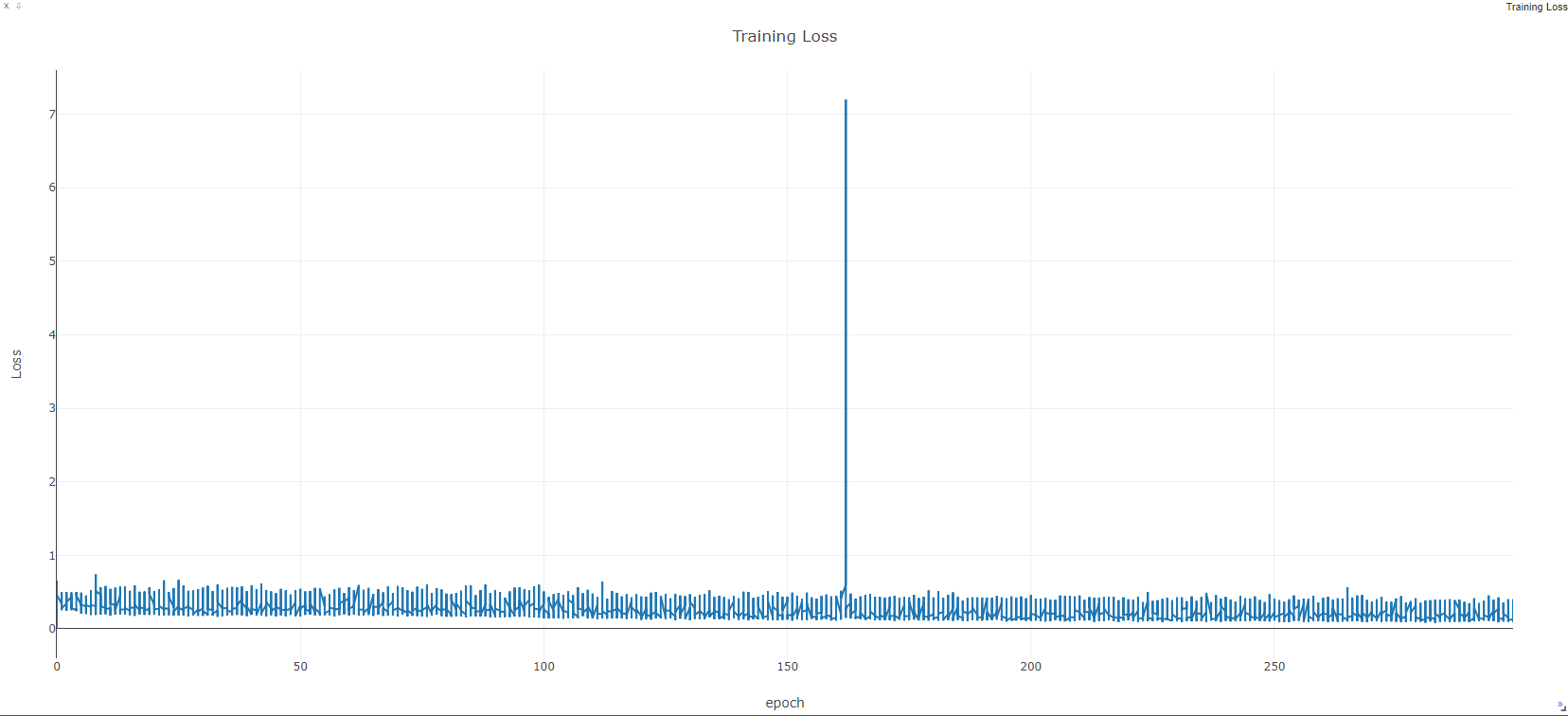
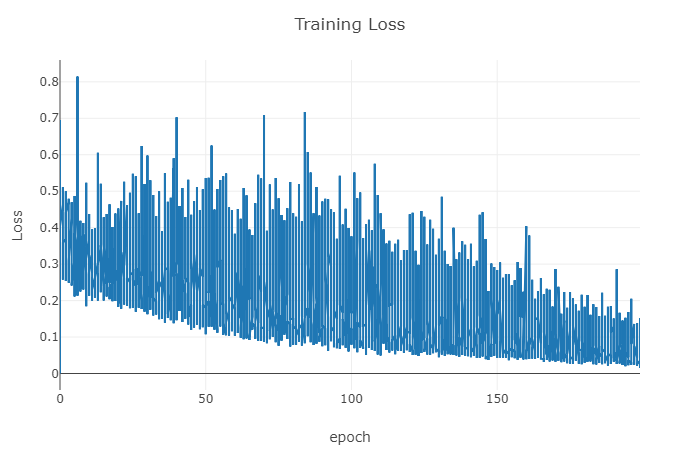
I am wondering why the training loss goes down and up and it looks too noisy?
Am I doing something wrong when I plot them or my learning rate is high? or something else? my bach size is 1
This is the training code.
criterion = nn.NLLLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
print("starting training")
#training loop
def train_model():
vis = visdom.Visdom()
loss_window = vis.line(X=torch.zeros((1,)).cpu(),
Y=torch.zeros((1)).cpu(),
opts=dict(xlabel='epoch',
ylabel='Loss',
title='Training Loss',
legend=['Loss']))
for epoch in range(300): # loop over the dataset multiple times
for i, data in enumerate(train_loader, 0):
# get the inputs
t_image, mask = data
t_image, mask = Variable(t_image.to(device)), Variable(mask.to(device))
# zeroes the gradient buffers of all parameters
optimizer.zero_grad()
# forward + backward + optimize
outputs = model(t_image) # forward
loss = criterion(outputs, mask) # calculate the loss
loss.backward() # back propagation
optimizer.step() # update gradients
#print('Epoch {}, Loss {}'.format(epoch, loss.item()))
vis.line(
X=torch.ones((1, 1)).cpu()*epoch,
Y=torch.Tensor([loss]).unsqueeze(0).cpu(),
win=loss_window,
update='append')