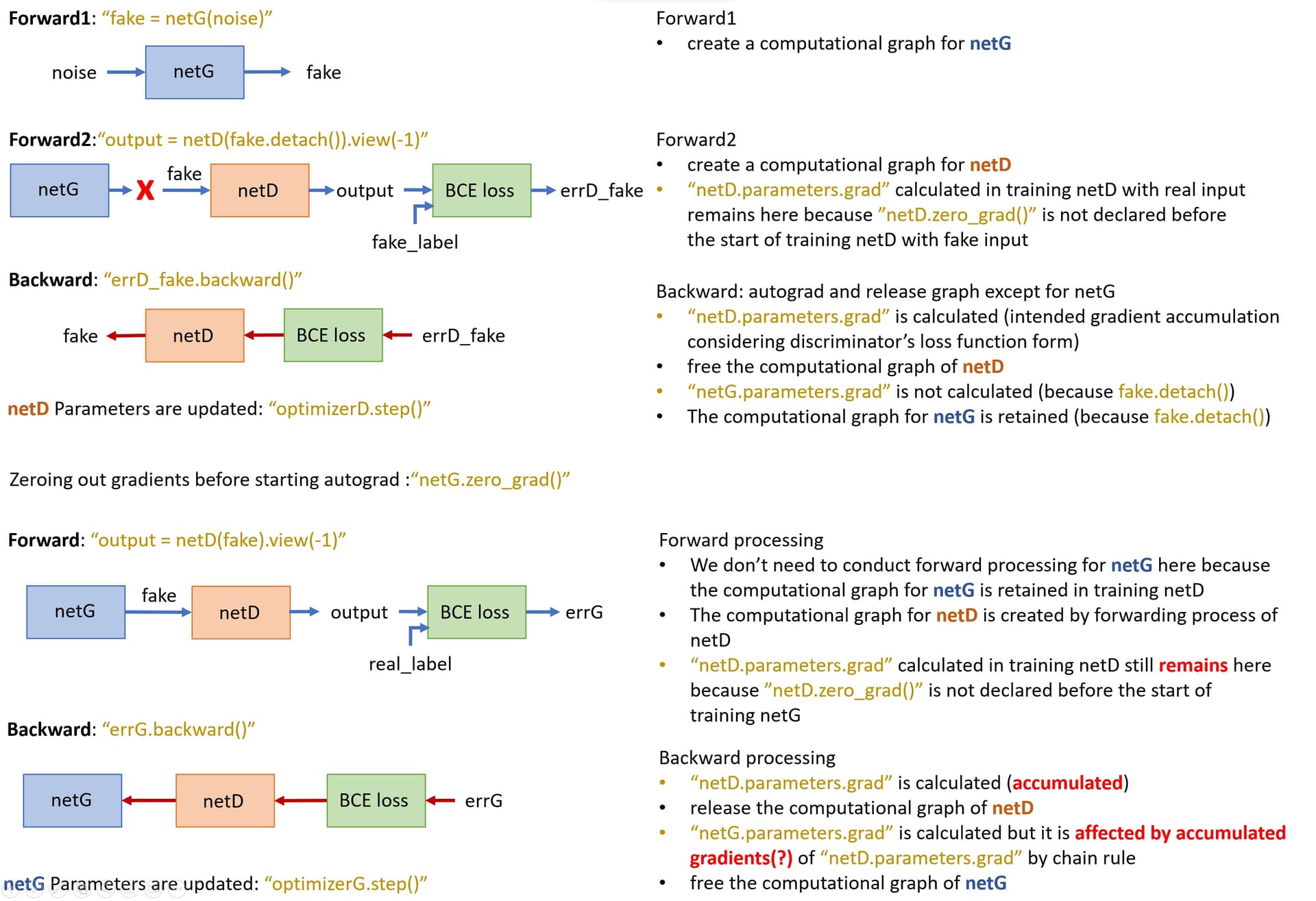
I have two quick questions about the Pytorch DCGAN tutorial code.
To avoid gradient accumulation, “netD.zero_grad()” looks like required before “errD_fake.backward()” but not. Why?
In the training of discriminator network, “fake.detach()” is used, which means the fake network is detached from the graph, and gradient calculation is not conducted in “errD_fake.backward()”. Then, why do we have to initialize grad of netG (“netG.zero_grad()”) before backpropagation?
The gradients w.r.t. errD_real and errD_fake are accumulated and optimizerD.step() is called once to update the parameters of the discriminator.
You could also update the discriminator separately but I don’t know if this would negatively affect the training.
You would still need to zero out the gradient from the generator update performed in the previous iteration.
Thank you for the clear answer.
However, I still get confused with gradient accumulation in training netG.
I attached the simple figure describing my questions here.
Please refer to the figure and let me know what I misunderstand. (my questions are red colored)
It looks as if ‘netD.parameters.grad’ is accumulated while training netG, but the gradient accumulation doesn’t affect autograd result of ‘netG.parameters.grad’ (I checked it by testing toy codes).
I don’t understand why accumulated gradients of netD parameters don’t affect autograd result of netG parameters.
To your question, netD’s already accumulated gradients do not affect the backpropagation.
The accumulated gradients do not participate in the backpropagation (or chain rule).
i.e., When calculating gradients for the current forward data, at a particular layer, only the gradients from current forward data are used to calculate gradients to be backpropagated.
Your answer explains a lot to me, and do you know where I can get more details about “When calculating gradients for the current forward data, at a particular layer, only the gradients from current forward data are used to calculate gradients to be backpropagated”?
You can read any standard blog about chain rule I guess.
Pytorch’s backpropagation is the same as any standard chain rule and gradient calculation.
If it helps, you can also check using a simple program like below to verify that the .grad is just a buffer to hold/accumulate gradients & they do not participate in backpropagation.
import torch
import torch.nn as nn
import torch.nn.functional as F
class NN(nn.Module):
def __init__(self) -> None:
super().__init__()
self.lin0 = nn.Linear(4,6)
self.lin1 = nn.Linear(6,3)
def forward(self, x):
out = self.lin0(x)
out = F.relu(out)
out = self.lin1(out)
return out
if __name__ == "__main__":
net = NN()
data = torch.randn(2,4,requires_grad=True)
def print_grad():
print(f"data grad {data.grad}")
print(f"lin0 grad {net.lin0.weight.grad}")
print(f"lin1 grad {net.lin1.weight.grad}")
def zero_grad():
# zero grad on both data and model
net.zero_grad()
data.grad = None
print("forward 0")
out = net(data)
out.sum().backward()
print_grad()
zero_grad()
print("grads after zero_grad")
print_grad()
print("forwarding 2 times without zero_grad()")
out = net(data)
out.sum().backward()
out = net(data)
out.sum().backward()
print_grad()
Thank you for the toy code to help my understanding.
I summarized what I understood about your answer here.
If you don’t mind, would you take a look at the attached figure and let me know whether my understanding is correct or not?
dL_2 / do_2 is calculated by relationship between netB output and netB input (not parameters)`
Note that w_1 could appear in dL_2 / do_2. It depends on the functionality of netB.
For instance, if netB calculates w_1 * o_2 and L_2 is squared error (i.e., (w_1 * o_2 - t) ^2) with target t, then dL_2 / do_2 = 2 * (w_1*o_2 - t) * w_1.
maybe you already know this. Just wanted to mention it.
You are right about " w_1 could appear in dL_2 / do_2", but what I intended to talk about in “dL_2 / do_2 is calculated by the relationship between netB output and netB input (not parameters)” is “dL_2/do_2 doesn’t depend on partial derivatives w.r.t. w_1 (dw_1)”.
I made the statement confusing as if the meaning is “dL_2 / do_2 doesn’t depend on w_1”.
Do you think “dL_2/do_2 doesn’t depend on partial derivatives w.r.t. w_1 (dw_1)'” is correct?