Hello.
When I applied Quantization to a convolution based model, I found the inference latency is increased.
For specific example, a latency of a single conv2d layer(input_channel:4, output_channel:16) is about 1.249ms which is measured by PyTorch Profiler. After quantization, the latency of the same layer is about 4.716ms
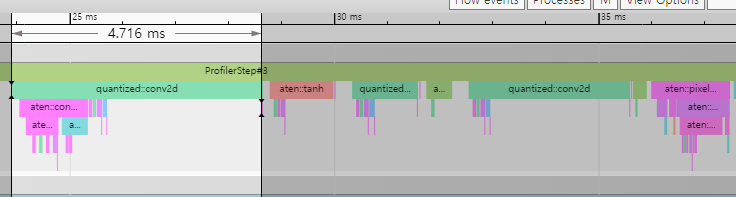
I think the reason might be the output_channel is bigger than input_channel. is this right?
and I want to know the specific purpose of the quantized conv layer’s followings(e.g. aten::contiguous, aten::empty_like etc) If I want to know about these operators, where should I look?
Thanks in advance for your help.