I already solved this problem code wise, but I don’t know why what I did worked and want an explanation.
I was doing SSD bounding box detection and loss was okay in the first epoch. Then in the second epoch, it suddenly jumped to 5000-10000 range. This loss jump was coming from my loss function for the location of bounding box, meaning x y coordinates of where the object is; loss function for labeling, classifying the class of the object being detected was okay, going down gradually as expected
I figured out that if I don’t do data augmentations like random flip, random crop, random hue change and stuff of those sorts in my data loader, the loss for xy coordinates doesn’t go crazy. Then I set the random seed and enabled data augmentation, and it also worked fine and loss was stable.
What happens, if you change the seed to another number?
I assume you got lucky with this seed and the training might be generally unstable, which is a bad sign.
Thank you so much for your reply.
I changed the seed from 1234 to 12345 and it is working just as fine.
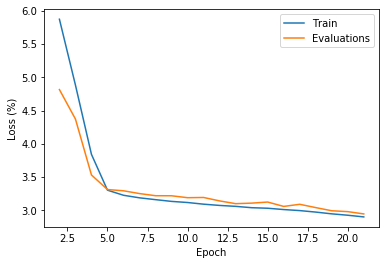
Below is the loss at the beginning of the 2nd epoch, before, meaning before setting seed values, it was in the range of 5000 to 10000. Now, it is slightly below the loss for the first epoch, which is exactly what I expect it to be.
I guess setting any kind of seed number is important for data augmentation that uses random number generator. I am not quite sure why.
I did another random number and it was very stable learning curve and detection was not that terrible although I think I need a few more epochs.
What I dont understand is that the loss jumped from the second epoch, when I did not set the seed, but was rather stable in the first round? Why would this be?
Different seeds might create “lucky” or “bad” runs.
Usually, it’s a bad sign if only a specific seed is letting your model train properly while others fail.
If you are seeing the loss explosion for all (or the majority) of vanilla runs, and observe proper training for seeding the code with random values, this might be some bug I cannot explain, and we would need to dig into it.
Could you create an executable code snippet, which would demonstrate the observed behavior?
I am sorry for the late response.
I found some questionable codes in my program, and I am now looking into it. But I am thinking the weird behavior might be due to this issue.
However, thank you for your engagement.