I read a artical which said:
"The Picture explain the action of DataParallel:
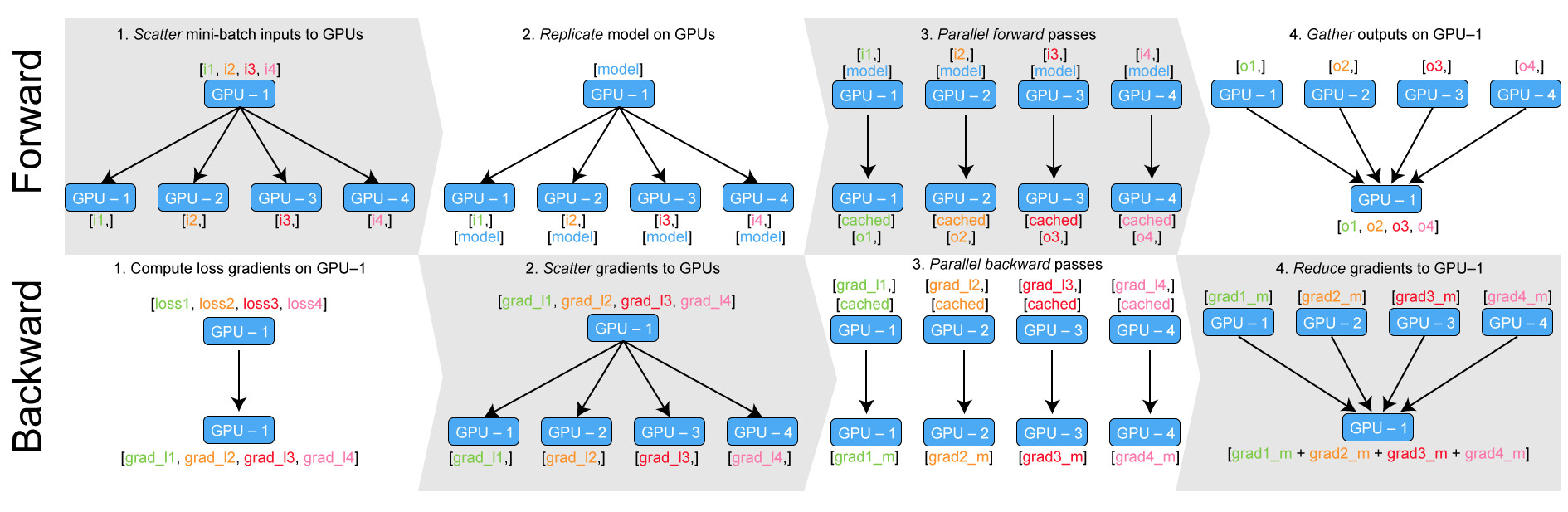
In the forth step of forward, all parallel computations are aggretated on GPU1 which is a good thing for many classification problems."
I don’t understand why design so. Why not computate loss and backward on each GPU. Then final gradients are aggretated on GPU1 at last to update parameters. And I also don’t understand why it’s a good thing for classification?
can anyone answer my question? Thanks a lot!