The design of my model are shown follow:
CharLSTM:
class CharLSTM(nn.Module):
def __init__(self, config):
super(CharLSTM, self).__init__()
self.config = config
self.char_embedding = nn.Embedding(self.config.char_num, self.config.char_dim)
self.char_lstm = nn.LSTM(self.config.char_dim, self.config.char_hidden_dim, batch_first=True)
def forward(self, x):
x = x.unsqueeze(0) # (1, char_num)
x = Variable(x)
if self.config.transfer_if_gpu:
x = x.cuda()
x = self.char_embedding(x) # (char_num, char_dim)
out, (h, _) = self.char_lstm(x) # (1, 1, char_hidden)
return h
WordLSTM
class DLSA(nn.Module):
def __init__(self, config):
super(DLSA, self).__init__()
self.config = config
self.char_lstm = CharLSTM(self.config)
self.word_lstm = nn.LSTM(self.config.char_hidden_dim, self.config.transfer_word_hidden_dim, batch_first=True)
self.linear = nn.Linear(self.config.transfer_word_hidden_dim, self.config.transfer_label_num)
def forward(self, sent, label):
word_vectors = torch.FloatTensor()
for word in sent:
char_list = torch.LongTensor(word) # (char_num,)
char_hidden = self.char_lstm(char_list) # (1, char_num, char_hidden)
char_hidden = char_hidden.squeeze(0) # (1, char_hidden)
word_vectors = torch.cat((word_vectors, char_hidden), 0) # (word_num, char_hidden)
input = Variable(word_vectors)
if self.config.transfer_if_gpu:
input = input.cuda()
input = input.unsqueeze(0)
_, (h, _) = self.word_lstm(input) # (1, 1, word_hidden)
h = h.view(-1) # (word_hidden, )
output = self.linear(h) # (5,)
scores = F.softmax(output) # (5,)
cls_loss = -1 * torch.log(scores[label]) # 0-dim, scale
return cls_loss
train
model = DLSA(config)
if config.transfer_if_gpu:
model.cuda()
parameters = filter(lambda p: p.requires_grad, model.parameters())
optimizer = create_optimizer(parameters, config.transfer_optimizer, config.transfer_learning_rate, config.transfer_weight_decay)
for e in range(config.transfer_epochs):
print "Epoch: ", e + 1
model.train()
if e % config.transfer_adjust_every == 0:
adjust_learning_rate(optimizer, e, config.transfer_learning_rate, config.transfer_adjust_every)
print len(train_batch)
for sentence_list in train_batch:
optimizer.zero_grad()
if len(sentence_list) == 0:
continue
for sent, label in sentence_list:
cls_loss = model(sent, label)
cls_loss.backward()
# torch.nn.utils.clip_grad_norm_(model.parameters(), config.transfer_clip_norm, norm_type=2)
optimizer.step()
f1 = evaluate_dev(trial_batch, model)
print "Trial f1: ", f1
if f1 > best_f1:
best_f1 = f1
best_model = copy.deepcopy(model)
print “Finish with best dev f1 {0}”.format(best_f1)
evaluate_test(test_batch, best_model)
I got the resullt shown follow
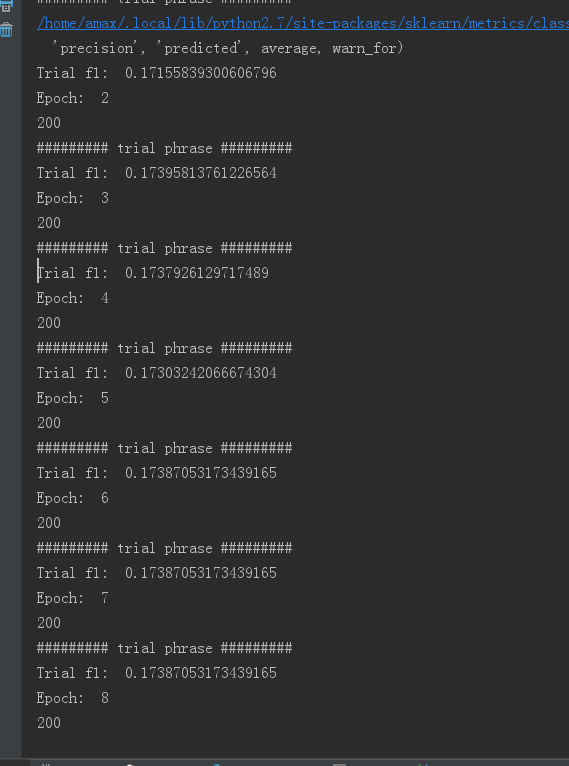
I don’t know where is my mistake, Can you help me