I am trying to train a sentiment analysis model for detecting whether an Amazon review is positive or negative. I am using the following model:
class GRUModel(torch.nn.Module):
def __init__(self):
super(GRUModel, self).__init__()
self.embedding = torch.nn.Embedding(5002, 100)
self.gru = torch.nn.GRU(100, 50, batch_first=True)
self.linear = torch.nn.Linear(50, 1)
def forward(self, x, lengths):
x = self.embedding(x)
x = torch.nn.utils.rnn.pack_padded_sequence(x, lengths, batch_first=True)
x = self.gru(x)[1][0]
x = torch.sigmoid(self.linear(x))
return x
My data is usual python array with integer indices, which I then convert to torch tensors with the following collate function:
def collate_fn(args):
target = [t for _, t in args]
data = [d for d, _ in args]
data.sort(key=lambda x: len(x), reverse=True)
lengths = [len(d) for d in data]
data = torch.nn.utils.rnn.pad_sequence([torch.tensor(d, dtype=torch.int64) for d in data], batch_first=True)
return data, torch.tensor(target, dtype=torch.float32), lengths
This is my training loop:
model = GRUModel().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
for e in range(epochs):
running_train_loss, running_test_loss = 0, 0
for data, target, lengths in tqdm(train_data_loader, 'training epoch {}'.format(e)):
optimizer.zero_grad()
outputs = model(data.to(device), lengths)
loss = loss_fn(outputs, target.to(device).view((-1, 1)))
running_train_loss += loss.item()
loss.backward()
optimizer.step()
with torch.no_grad():
for data, target, lengths in tqdm(test_data_loader, 'evaluating epoch {}'.format(e)):
outputs = model(data.to(device), lengths)
loss = loss_fn(outputs, target.to(device).view((-1, 1)))
running_test_loss += loss.item()
train_loss = running_train_loss / len(train_data_loader)
test_loss = running_test_loss / len(test_data_loader)
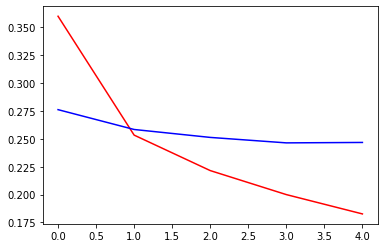
The train loss decreases very slowly, and the validation loss increases from the start. I trained the model for 5 epochs. Below is the plot of learning curves, where red is training loss and blue is validation loss
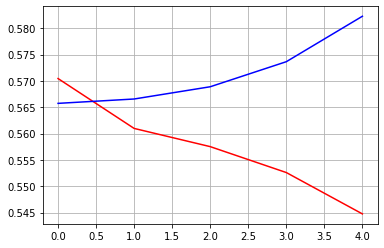
However, when I train the exact same architecture in Keras, the model gets very good loss after single epoch! After first epoch validation loss is about 0.27 and by the fifth epoch it gets close to 0.25.
m_input = keras.layers.Input(shape=(None,))
x = keras.layers.Embedding(5002, 100, mask_zero=True)(m_input)
x = keras.layers.GRU(50)(x)
x = keras.layers.Dense(1, activation='sigmoid')(x)
model = keras.models.Model(m_input, x)
print(model.summary())
model.compile(loss='binary_crossentropy', optimizer=keras.optimizers.Adam(1e-3))
class Sequence(keras.utils.Sequence):
def __init__(self, data, target):
super(Sequence, self).__init__()
self.data = data
self.target = target
self.batch_size = 256
def __len__(self):
return int(np.ceil(len(self.data) / self.batch_size))
def __getitem__(self, idx):
start_idx = self.batch_size * idx
end_idx = start_idx + self.batch_size
data = self.data[start_idx:end_idx]
target = self.target[start_idx:end_idx]
return keras.preprocessing.sequence.pad_sequences(data), np.array(target)
train_generator = Sequence(data_train, target_train)
test_generator = Sequence(data_test, target_test)
model = build_keras_model()
history = model.fit_generator(train_generator, validation_data=test_generator, epochs=5, verbose=2)
Also in torch one epoch took about 9 seconds, and in Keras one epoch took about 4 minutes and 45 seconds.
Please help me solve this mystery, I am trying to find an error in my PyTorch code for over a week ![]()