Hi,
I’m trying to modify a word-level transformer to a character one to do some spelling corrections. The source code is from:Language Translation with nn.Transformer and torchtext — PyTorch Tutorials 1.9.0+cu102 documentation
I shared the embedding weight and projection weight. But my result was terrible, even when I put src and tgt same as gold text. The greedy decoder cannot even form a correct English word. I noticed that my val loss would not reduce after several epochs’ training.
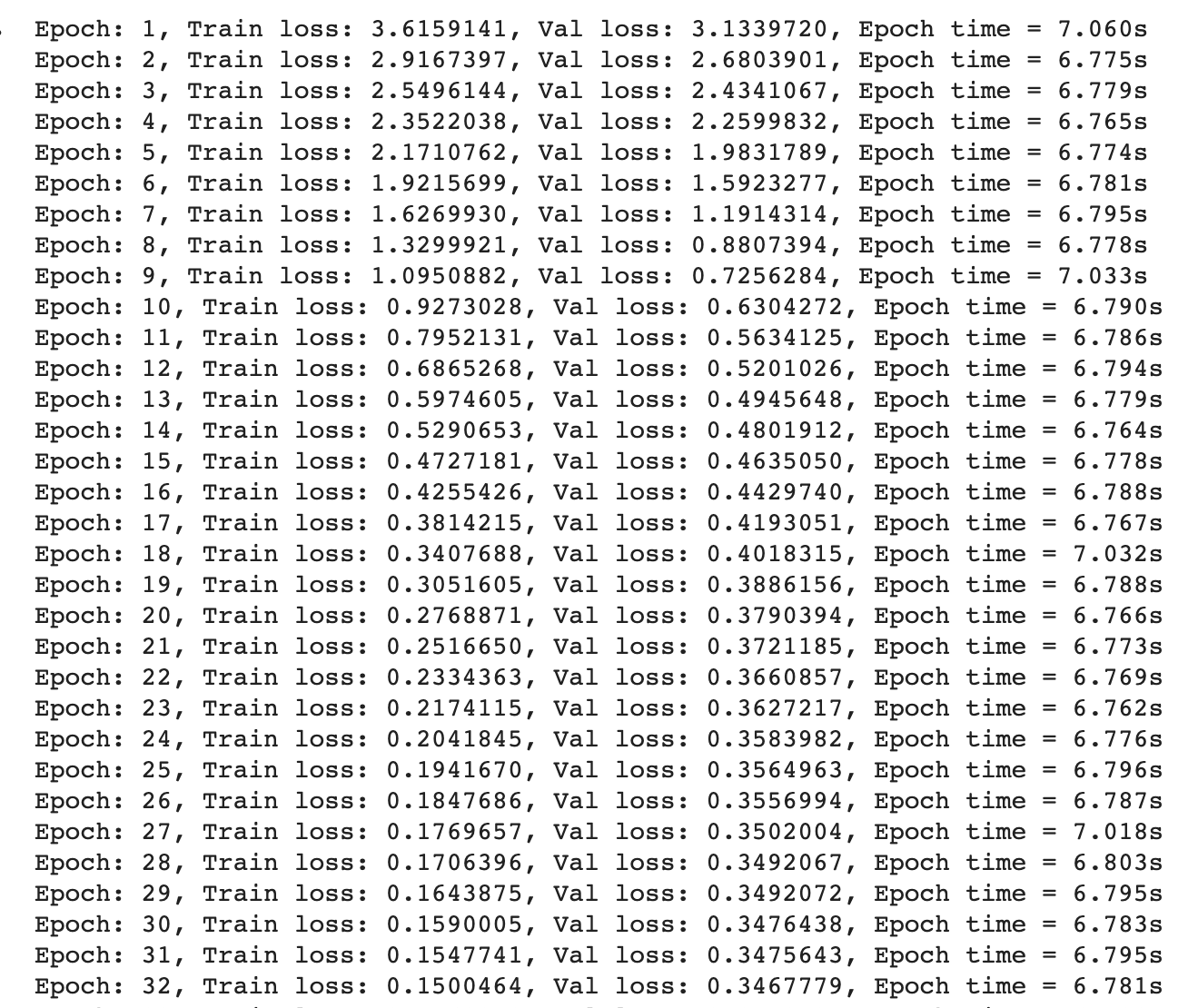
(This is a model with much less layers and heads)
I tried a lot of parameter combinations but none of them worked.
May I ask is there any key modification should be done in character level transformer? (The vocabulary size of mine is 80+, including caps, not sure does this matter)
Thank you 