I’m training a simple XOR neural network to familiarize myself with PyTorch.
My code is:
class XOR(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(2,2)
self.fc2 = nn.Linear(2,1)
self.optimizer = torch.optim.Adam(self.parameters())
self.loss = nn.BCELoss()
self.lh = []
def forward(self, x):
x = torch.tanh(self.fc1(x))
x = torch.sigmoid(self.fc2(x))
return x
def step(self, batch, truth):
self.optimizer.zero_grad()
preds = self(batch)
loss = self.loss(preds, truth)
loss.backward()
self.lh.append(loss)
self.optimizer.step()
def fit(self, epoch):
d1 = torch.FloatTensor([[1,1]]); t1 = torch.FloatTensor([[0]])
d2 = torch.FloatTensor([[1,0]]); t2 = torch.FloatTensor([[1]])
d3 = torch.FloatTensor([[0,1]]); t3 = torch.FloatTensor([[1]])
d4 = torch.FloatTensor([[0,0]]); t4 = torch.FloatTensor([[0]])
for _ in range(epoch):
self.step(d1,t1)
self.step(d2,t2)
self.step(d3,t3)
self.step(d4,t4)
def test(self):
net = self
d1 = torch.FloatTensor([[1,1]]); d2 = torch.FloatTensor([[1,0]]); d3 = torch.FloatTensor([[0,1]]); d4 = torch.FloatTensor([[0,0]]);
print(f" 1,1 : {net(d1).item()}\n 1,0 : {net(d2).item()}\n 0,1 : {net(d3).item()}\n 0,0 : {net(d4).item()}\n ")
def show(self):
l = len(self.lh)
y = np.array(self.lh)
x = np.arange(l)
plt.plot(x,y)
plt.show()
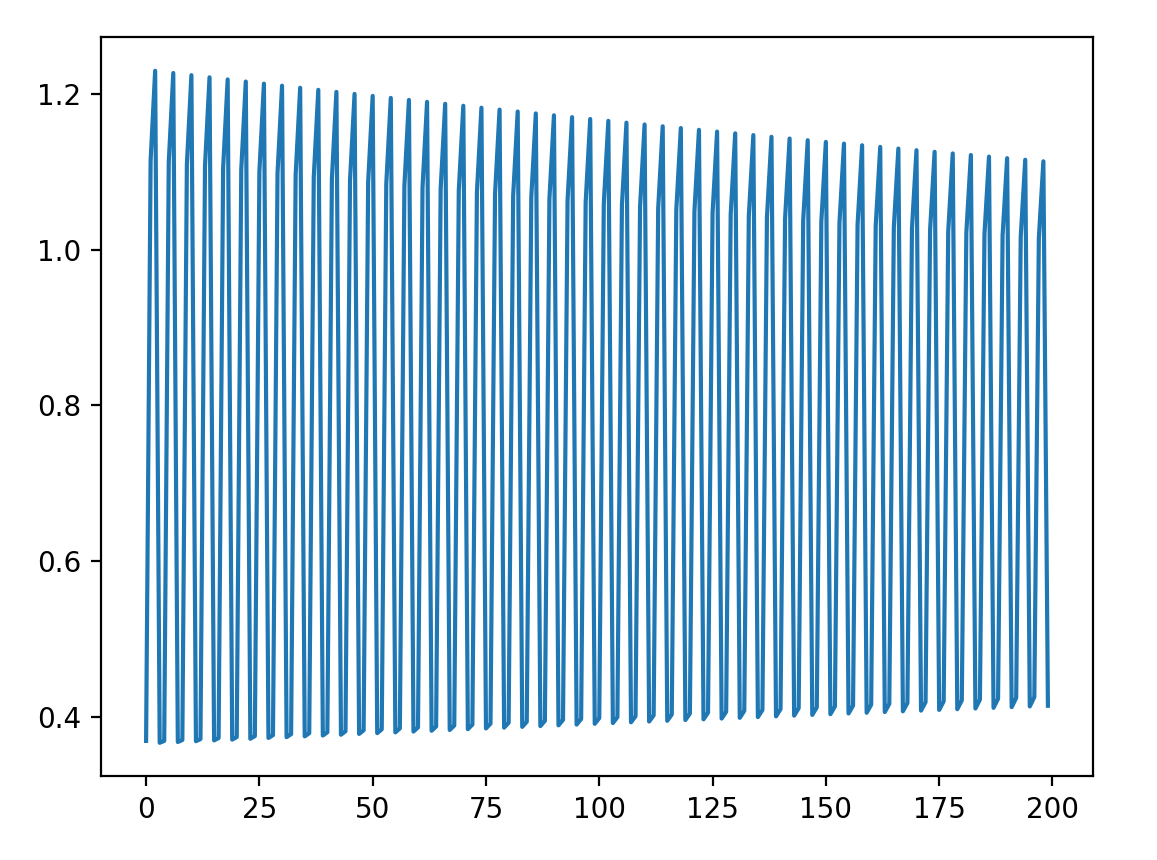
When I run it, this neural network is not capable of overfitting to the training data. The loss fluctuates around but no improvement is being made even when I run the fit method for 1000s of epochs. What am I doing wrong here? I am really confused. Any help would be appreciated ![]()
Loss graph: