Hi,
I just run your code snipper, but there is something wrong, it raised RuntimeError about call .backward on the computation graph which had been freed. And a.grad is still None except the first iteration, so it learned nothing. Additionally, your learning_rate is too high.
I write a snippet based on yours, and it works now.
n = 70 # num of points
# x is a tensor
x = torch.linspace(0, 10, steps=n)
k = torch.tensor(2.5)
# y is a tensor
y = k * x + 5 * torch.rand(n)
# loss function
def mse(y_hat, y):
return ((y_hat - y) ** 2).mean()
a = torch.tensor(-1., requires_grad=True)
a = nn.Parameter(a)
lr = 0.005
for t in range(10):
print(t, ':', a.grad, a.requires_grad)
if a.grad is not None:
a.grad.zero_()
y_hat = a * x
loss = mse(y_hat, y)
loss.backward()
#print(t, 'after backward:', a.grad, a.requires_grad, a.is_leaf)
a = (a.data - lr * a.grad).requires_grad_(True)
#print(t, 'after update:', a.requires_grad, a.is_leaf)
plt.scatter(x, y)
plt.scatter(x, y_hat.detach())
plt.show()
- You should calculate y_hat in the loop, otherwise, there will raise a RuntimeError mentioned above.
- If you assign
adirectly in each iteration,awill only have grad in the first iteration sinceawill be a non_leaf Variable and its grad will be None.
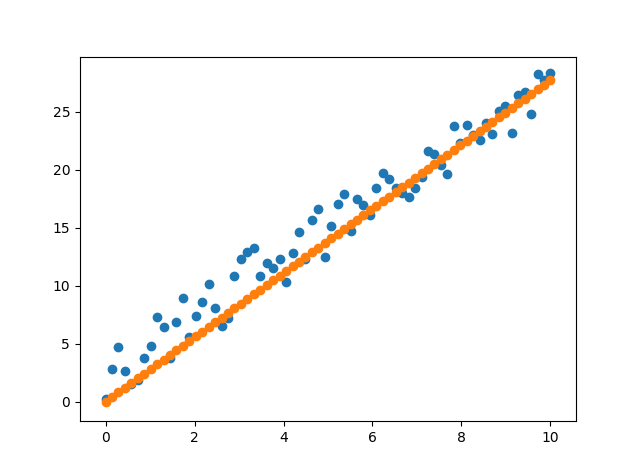
EDIT: oh, I forgot to zero a.grad and I have correct it in the snippet.