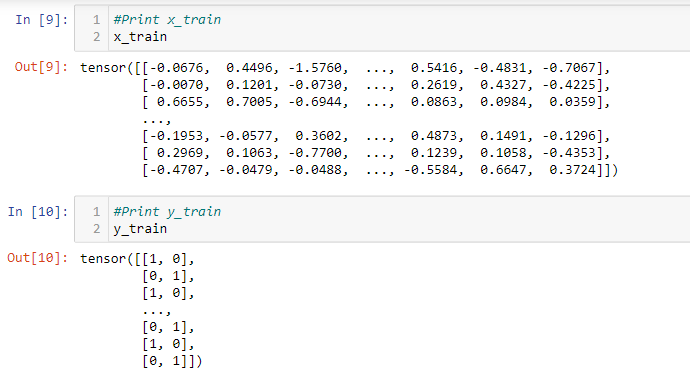
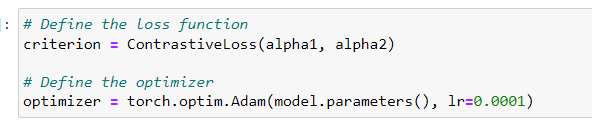
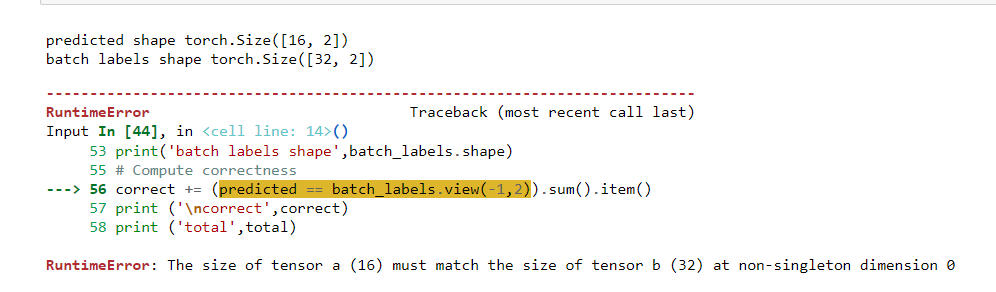
I’m constantly getting an accuracy of 0.00 and not able to rectify the issue for the same. Below are my code and snippets to my results that I’m getting. Please help me through it.
My model architecture :
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from sklearn.model_selection import train_test_split
import torch.nn.functional as F
class CustomDataset(Dataset):
def __init__(self, features, labels):
self.features = features
self.labels = labels
def __len__(self):
return len(self.features)
def __getitem__(self, index):
x = self.features[index]
y = self.labels[index]
return x, y
#return self.features[index], self.labels[index]
class RelationAwareFeatureExtractor(nn.Module):
def __init__(self):
super(RelationAwareFeatureExtractor, self).__init__()
# ConvNet layers
#self.conv1 = nn.Conv2d(4, 8, kernel_size=3, stride=3, padding=1)
self.conv1 = nn.Conv2d(4, 16, kernel_size=3, stride=3, padding=1)
#self.pool1 = nn.MaxPool2d(2, 2)
#self.conv2 = nn.Conv2d(8, 16, kernel_size=3, stride=3, padding=1)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, stride=3, padding=1)
self.conv3 = nn.Conv2d(32, 64, kernel_size=3, stride=3, padding=1)
self.dropout1 = nn.Dropout(0.25)
self.fc1 = nn.Linear(64*2*1, 1024)
self.fc2 = nn.Linear(1024, 256)
self.fc3 = nn.Linear(256, 125)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
#x = self.pool1(x)
x = F.relu(self.conv2(x))
x = self.dropout1(x)
x = F.relu(self.conv3(x))
#x = F.relu(self.conv4(x))
# Flatten the tensor before fully connected layers
x = torch.flatten(x, start_dim=1) # Flatten dimensions except batch dimension
# Fully connected layers
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
class SelfAttention(nn.Module):
def __init__(self, hidden_size):
super(SelfAttention, self).__init__()
self.query = nn.Linear(hidden_size, hidden_size)
self.key = nn.Linear(hidden_size, hidden_size)
self.value = nn.Linear(hidden_size, hidden_size)
def forward(self, x):
# Add an extra dimension for seq_len
x = x.unsqueeze(1)
batch_size, seq_len, hidden_size = x.size()
# Compute Query, Key, and Value matrices
q = self.query(x)
k = self.key(x)
v = self.value(x)
# Compute attention scores
scores = torch.matmul(q, k.transpose(1, 2))
attention_weights = F.softmax(scores, dim=2)
# Compute the weighted sum of Value using attention weights
x = torch.matmul(attention_weights, v)
# Squeeze the extra seq_len dimension and return the result
x = x.squeeze(1)
return x
class ConditionalRandomFields(nn.Module):
def __init__(self, hidden_size, num_labels):
super(ConditionalRandomFields, self).__init__()
self.hidden_size = hidden_size
self.num_labels = num_labels
self.linear1 = nn.Linear(hidden_size, num_labels)
self.linear2 = nn.Linear(num_labels, 2)
#self.linear3 = nn.Linear(num_labels, 1)
def forward(self, x):
x = self.linear1(x)
x = F.log_softmax(x, dim=1)
x = self.linear2(x)
x = F.log_softmax(x, dim=1)
#x = self.linear3(x)
return x
class ContrastiveLoss(nn.Module):
def __init__(self, alpha1, alpha2):
super(ContrastiveLoss, self).__init__()
self.alpha1 = alpha1
self.alpha2 = alpha2
def binary_classification_loss(self, predicted_scores, target_labels):
# target_labels = torch.Tensor(target_labels)
loss = F.binary_cross_entropy_with_logits(predicted_scores, target_labels.float())
return loss
def sparsity_loss(self, f_values, lambda2):
sparsity_term = lambda2 / 2 * torch.sum(f_values)
return sparsity_term
def temporal_smoothness_loss(self, f_values, lambda1):
smoothness_term = lambda1 / (f_values.size(0) - 1) * torch.sum((f_values[:] - f_values[:]) ** 2)
return smoothness_term
def forward(self, outputs, targets):
loss = self.binary_classification_loss(outputs, targets) + \
self.alpha1 * self.temporal_smoothness_loss(outputs, self.alpha1) + \
self.alpha2 * self.sparsity_loss(outputs, self.alpha2)
return loss
class AnomalyDetector(nn.Module):
def __init__(self):
super(AnomalyDetector, self).__init__()
# Feature extractor
self.feature_extractor = RelationAwareFeatureExtractor()
# Self-attention layer
self.self_attention = SelfAttention(125)
# Conditional random fields layer
self.conditional_random_fields = ConditionalRandomFields(125,2)
def forward(self, x):
# Extract features
x = self.feature_extractor(x)
x = self.self_attention(x)
log_likelihood = self.conditional_random_fields(x)
return log_likelihood
My model :
# Initialize lists to store accuracy values
train_accuracy_history = []
# Training loop
best_val_loss = float('inf')
patience = 3
train_loss_history = []
verbose = True
l2_lambda = 0.0001
scheduler = optim.lr_scheduler.StepLR(optimizer,step_size=2, gamma=0.6)
for epoch in range(num_epochs):
model.train()
train_loss = 0.0
correct = 0
total = 0
model.to('cuda')
for batch_data, batch_labels in train_loader:
batch_data = batch_data.to('cuda')
batch_labels = batch_labels.to('cuda')
optimizer.zero_grad()
# Forward pass
output = model(batch_data)
output = torch.reshape(output, (-1,2)) #reshape for uniformity with labels
batch_labels = batch_labels.view(-1,2)
# Apply sigmoid activation
output = torch.sigmoid(output)
# Compute loss
ce_loss = criterion(output, batch_labels.float())
l2_reg = 0.0
for param in model.parameters():
l2_reg += torch.norm(param, p=2)
# Combine the cross-entropy loss and L2 regularization term
loss = ce_loss + l2_lambda * l2_reg
# Backward pass and optimization
loss.backward()
optimizer.step()
train_loss += loss.item()
# Apply a threshold (e.g., 0.5) to the predicted probabilities to get binary predictions
threshold = 0.5
predicted_binary = (output > threshold).long()
total += batch_labels.size(0)
# Convert one-hot encoded labels to class indices
true_class_indices = torch.argmax(batch_labels, dim=1)
predicted_class_indices = torch.argmax(output, dim=1)
# Compute correctness
correct = (predicted_class_indices == true_class_indices).sum().item()
train_loss /= len(train_loader)
accuracy = correct / total
train_accuracy_history.append(accuracy)
train_loss_history.append(train_loss)
if verbose:
print(f"\nEpoch [{epoch+1}/{num_epochs}] | Train Loss: {train_loss:.4f} | Train Accuracy: {accuracy:.2f}")
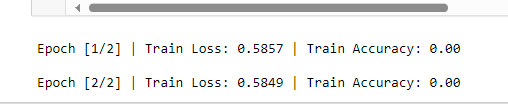
The results for all the variables:
batch_lables torch.Size([32, 2])
values of batch labels tensor([[1, 0],
[0, 1],
[0, 1],
[0, 1],
[1, 0],
[0, 1],
[1, 0],
[0, 1],
[1, 0],
[1, 0],
[1, 0],
[1, 0],
[0, 1],
[1, 0],
[1, 0],
[0, 1],
[0, 1],
[0, 1],
[0, 1],
[0, 1],
[0, 1],
[0, 1],
[0, 1],
[1, 0],
[0, 1],
[0, 1],
[1, 0],
[1, 0],
[1, 0],
[1, 0],
[1, 0],
[1, 0]], device=‘cuda:0’)
loss tensor(0.5849, device=‘cuda:0’, grad_fn=)
train_loss 0.5849115252494812
output shape tensor([[4.9999e-01, 2.1466e-05],
[2.4545e-03, 4.9938e-01],
[7.5752e-04, 4.9981e-01],
[1.4673e-04, 4.9996e-01],
[5.0000e-01, 9.8606e-07],
[9.1912e-06, 5.0000e-01],
[5.0000e-01, 5.8453e-08],
[2.3587e-08, 5.0000e-01],
[5.0000e-01, 1.5152e-05],
[5.0000e-01, 1.4352e-05],
[5.0000e-01, 2.6618e-09],
[5.0000e-01, 1.2842e-09],
[8.2781e-06, 5.0000e-01],
[4.9990e-01, 3.8262e-04],
[4.9999e-01, 2.6368e-05],
[7.3966e-05, 4.9998e-01],
[4.0752e-04, 4.9990e-01],
[6.2843e-07, 5.0000e-01],
[1.1220e-06, 5.0000e-01],
[4.8463e-05, 4.9999e-01],
[1.6277e-05, 5.0000e-01],
[4.8436e-09, 5.0000e-01],
[5.6053e-05, 4.9999e-01],
[5.0000e-01, 1.8994e-06],
[6.8412e-08, 5.0000e-01],
[1.1235e-05, 5.0000e-01],
[5.0000e-01, 2.2152e-06],
[5.0000e-01, 2.1542e-07],
[5.0000e-01, 8.0913e-08],
[5.0000e-01, 2.9406e-06],
[5.0000e-01, 6.0105e-07],
[5.0000e-01, 7.2529e-07]], device=‘cuda:0’, grad_fn=)
predicted shape torch.Size([32, 2])
total 32
correct 32
batch_lables torch.Size([32, 2])
values of batch labels tensor([[1, 0],
[0, 1],
[0, 1],
[1, 0],
[0, 1],
[1, 0],
[0, 1],
[1, 0],
[1, 0],
[0, 1],
[0, 1],
[0, 1],
[1, 0],
[0, 1],
[1, 0],
[0, 1],
[1, 0],
[0, 1],
[0, 1],
[0, 1],
[0, 1],
[1, 0],
[0, 1],
[0, 1],
[1, 0],
[0, 1],
[0, 1],
[1, 0],
[1, 0],
[0, 1],
[0, 1],
[0, 1]], device=‘cuda:0’)
loss tensor(0.5849, device=‘cuda:0’, grad_fn=)
train_loss 1.1698077917099
output shape tensor([[5.0000e-01, 6.2346e-06],
[1.6325e-04, 4.9996e-01],
[3.9786e-10, 5.0000e-01],
[5.0000e-01, 3.9346e-06],
[1.0348e-05, 5.0000e-01],
[5.0000e-01, 1.0870e-06],
[1.5962e-04, 4.9996e-01],
[5.0000e-01, 1.4197e-06],
[5.0000e-01, 1.1123e-06],
[2.0377e-11, 5.0000e-01],
[4.3959e-07, 5.0000e-01],
[8.7828e-05, 4.9998e-01],
[5.0000e-01, 1.3009e-06],
[2.0889e-09, 5.0000e-01],
[5.0000e-01, 1.9072e-06],
[4.2047e-09, 5.0000e-01],
[5.0000e-01, 1.9087e-05],
[3.3150e-06, 5.0000e-01],
[6.1616e-06, 5.0000e-01],
[2.3865e-05, 4.9999e-01],
[1.3672e-06, 5.0000e-01],
[5.0000e-01, 8.2635e-08],
[4.8798e-08, 5.0000e-01],
[8.0339e-04, 4.9980e-01],
[5.0000e-01, 7.3366e-10],
[7.4766e-04, 4.9981e-01],
[7.2240e-08, 5.0000e-01],
[5.0000e-01, 9.3968e-07],
[5.0000e-01, 1.2232e-07],
[4.8472e-06, 5.0000e-01],
[1.7843e-07, 5.0000e-01],
[4.3401e-07, 5.0000e-01]], device=‘cuda:0’, grad_fn=)
predicted shape torch.Size([32, 2])
total 64
correct 32
batch_lables torch.Size([32, 2])
values of batch labels tensor([[0, 1],
[0, 1],
[0, 1],
[1, 0],
[0, 1],
[1, 0],
[0, 1],
[1, 0],
[1, 0],
[1, 0],
[0, 1],
[0, 1],
[0, 1],
[0, 1],
[1, 0],
[0, 1],
[1, 0],
[1, 0],
[1, 0],
[1, 0],
[0, 1],
[1, 0],
[0, 1],
[1, 0],
[1, 0],
[0, 1],
[0, 1],
[1, 0],
[1, 0],
[1, 0],
[0, 1],
[0, 1]], device=‘cuda:0’)
loss tensor(0.5849, device=‘cuda:0’, grad_fn=)
train_loss 1.754693865776062
output shape tensor([[3.2622e-08, 5.0000e-01],
[1.1377e-06, 5.0000e-01],
[9.7437e-09, 5.0000e-01],
[5.0000e-01, 9.2407e-10],
[2.9195e-07, 5.0000e-01],
[5.0000e-01, 3.2914e-08],
[5.6732e-07, 5.0000e-01],
[5.0000e-01, 1.8954e-10],
[5.0000e-01, 3.9070e-10],
[5.0000e-01, 5.4501e-07],
[5.9386e-09, 5.0000e-01],
[2.1088e-09, 5.0000e-01],
[2.6133e-06, 5.0000e-01],
[6.1587e-09, 5.0000e-01],
[5.0000e-01, 5.3023e-09],
[3.0130e-06, 5.0000e-01],
[5.0000e-01, 3.0164e-06],
[5.0000e-01, 3.8356e-07],
[5.0000e-01, 1.9535e-08],
[5.0000e-01, 4.2265e-06],
[7.3028e-12, 5.0000e-01],
[5.0000e-01, 2.8367e-07],
[5.1866e-07, 5.0000e-01],
[5.0000e-01, 2.0071e-08],
[5.0000e-01, 1.4716e-05],
[6.3466e-08, 5.0000e-01],
[4.1371e-06, 5.0000e-01],
[5.0000e-01, 1.8174e-06],
[5.0000e-01, 2.7787e-07],
[5.0000e-01, 1.2637e-05],
[9.3368e-09, 5.0000e-01],
[2.9646e-06, 5.0000e-01]], device=‘cuda:0’, grad_fn=)
predicted shape torch.Size([32, 2])
total 96
correct 32
My features and labels size :

x_train and y_train :