Not sure if I understod it correctly but souldnt be it possible to convolve 1dimensional input, like I have 4096 Datasets with 45 floats ?
Is convolution on such an input even possible, or does it make sense to use convolution.
If yes how do I setup this ?
If not how yould you approach this problem ?
You can use nn.Conv1d to apply a convolution on a time signal.
The input shape should be [batch_size, channels, sequence_length].
Based on your description, it seems you are dealing with 4096 samples, each containing 45 time steps and a single channel?
If i reshape to [4096, 1, 27] (I removed 18 input values) I get this error:
RuntimeError: Given groups=1, weight of size [64, 27, 2], expected input[4096, 1, 27] to have 27 channels, but got 1 channels instead
when changing to [4096, 27, 1] it goes crazy like RuntimeError: cuDNN error: CUDNN_STATUS_BAD_PARAM
Propably the network isnt setup correctly.
I think I didn’t give enough information:
I have 3 3x3 pixel blocks, block 1/2 are different in time but block 3 is the same time as block 2.
Currently they are all flat shaped [4096, 27].
What would a single valide convolution layer look like and whats the best way to shape this data.
What are your Conv1d arguments?
I am not sure to understand here, but if you mean that you want to convolve over 3 time steps and your input data is [4096, 1, 27], this should work:
>> output_channels = 1
>> t = torch.rand(4096, 1, 27)
>> conv = torch.nn.Conv1d(1, output_channels, kernel_size=3, padding=1)
>> conv
Conv1d(1, 1, kernel_size=(3,), stride=(1,), padding=(1,))
>> conv(t).shape
torch.Size([4096, 1, 27])
Thank you, it somehow works.
I still not really understand the convolution/input thing but at least no errors get raised now.
sir i have a data set of 2968 rows and 100 columns and i can’t pass my the data to CNN please help me to prepare my data for passing and also explain the structure of 1d convolutional layers.
Hello @ptrblck,
Taking advantage of your answer, I would like to know how to apply a CNN for text processing.
Imagine that I have the pre-processed text (tokenized + PAD):
input = torch.tensor(
[
[1, 2, 0, 0],
[3, 4, 5, 6],
[7, 0, 0, 0]
]
)
What would the Conv1D layer look like for this scenario? I mean, what would the in_channels, out_channels, and kernel_size parameters be configured?
Thanks in advance
It depends a bit how you would like to process this input.
Currently your input has a shape of [3, 4], which is invalid for nn.Conv1d as well as nn.Conv2d.
If you want to use these two dimensions as the “spatial size”, i.e. similar to an input image, you would have to unsqueeze the batch and channel dimensions as:
input = input[None, None]
print(input.shape)
> torch.Size([1, 1, 3, 4])
Now you could use an nn.Conv2d layer with in_channels=1 and a kernel_size, which would have the same size or which would be smaller than the padded input of 3x4.
Note that you could also use one dimension as the channel dimension, which would then change the conv layer as well as the unsqueezing, so let me know what you would like to achieve. 
The tensor:
input = torch.tensor(
[
[1, 2, 0, 0],
[3, 4, 5, 6],
[7, 0, 0, 0]
]
)
is a batch of 3 preprocessed sentences in which I must represent as a dense vector. For instance [1, 2, 0, 0] represents the tokens id (and pad token) for the first sentence. Now I want to do something like it:
for each sentence in the batch.
I am using PyTorch Lightning (which helps a lot) but I am completely confused about how a CNN can be used for text representation.
I think that before passing the input through a convolution block, I could go through an embedding layer, which would produce a shaped tensor [3,4,768] (batch_size, sentence_size, representation_size).
If the input represents word indices then an embedding layer sounds reasonable.
I don’t fully understand the figure and how the convolution should be applied.
Are 3 sets of filters with different sizes used? If so, you would need three conv layers or would need to pad some filters.
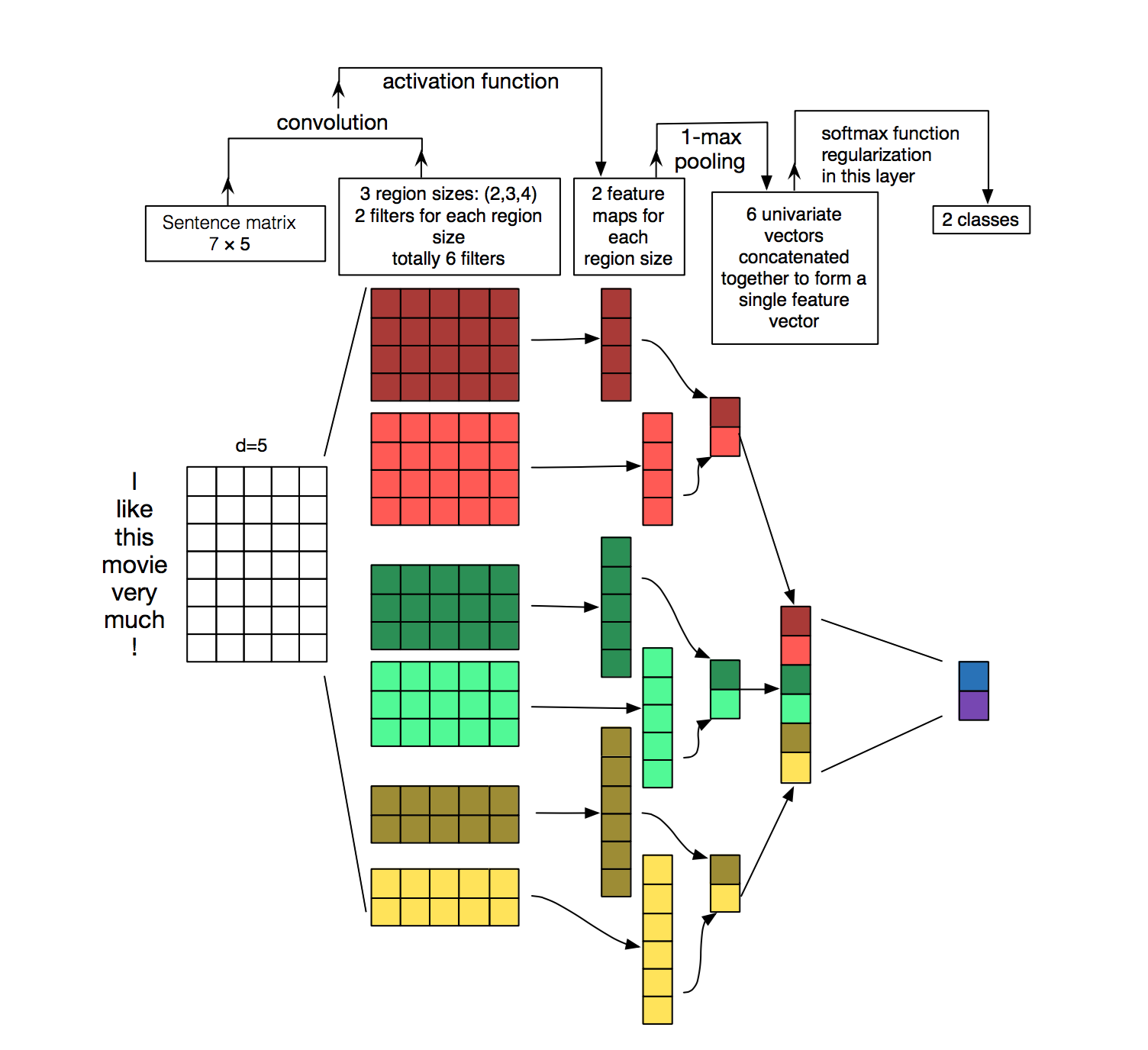
With this new image I think my objective becomes clearer:
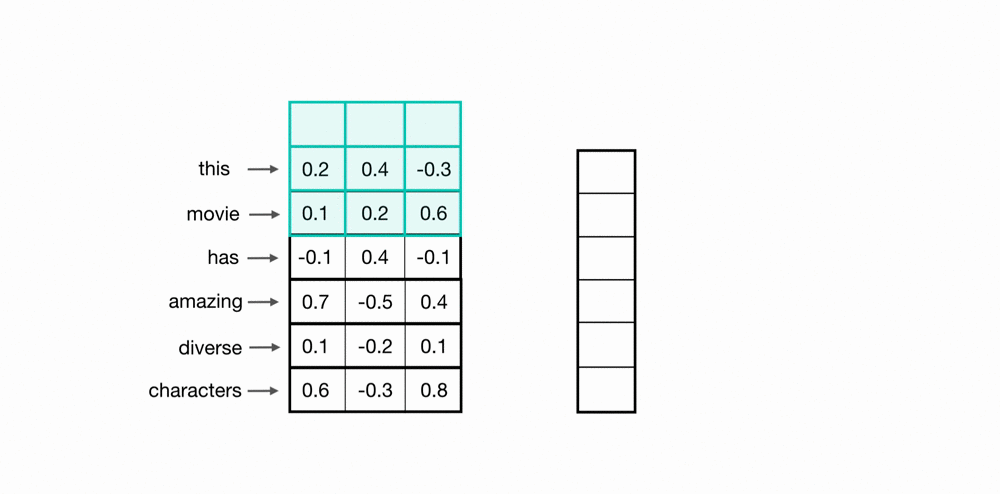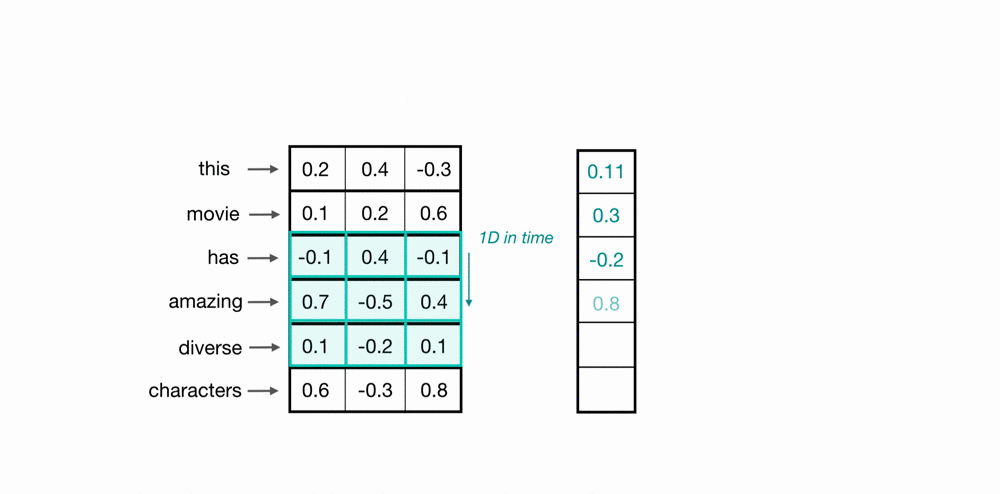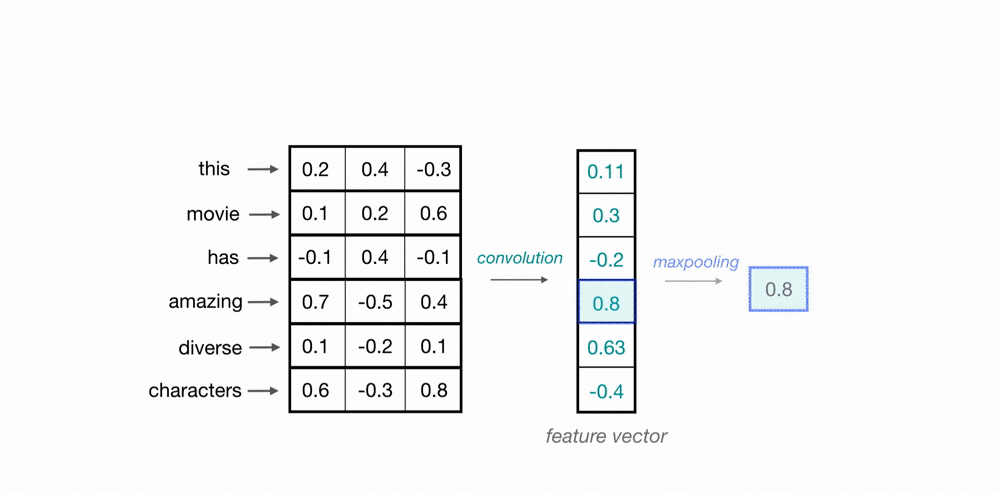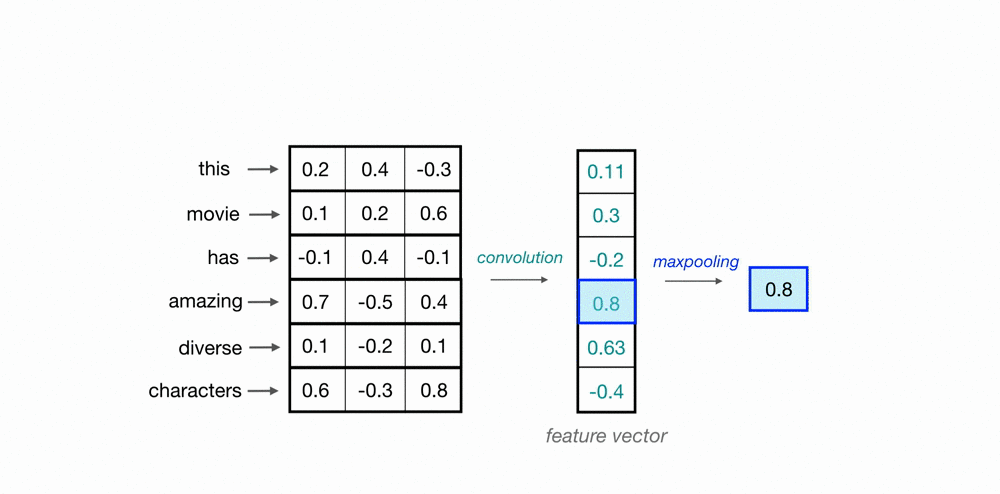
The filters/kernels are like a sliding window of different sizes. In the previous image, there are 2 filters of shape [2, 5], 2 filters of shape [3, 5], and other 2 filters of shape [4, 5].
For now, the model has only one embedding layer:
# batch of 3 sentences
input = torch.tensor(
[
[1, 2, 0, 0], # tokenized sentence 1
[3, 4, 5, 6], # tokenized sentence 2
[7, 0, 0, 0] # tokenized sentence 3
]
)
embedding_layer = torch.nn.Embedding(num_embeddings = 8, # vocabulary size
embedding_dim=5, # representation size
)
emb_out = embedding_layer(input) # torch.Size([3, 4, 5]) (batch_size, sentence_size, representation_size)
conv = torch.nn.Conv1d(in_channels=?,out_channels=?, kernel_size=?)
and, what I need to know is then, how to pass the embedding layer output into the convolutional layer as shown in the figure above.
Thanks in advance.
Thanks for the update.
In that case you would need to unsqueeze the channel dimension via:
emb_out = emb_out.unsqueeze(1)
and I would use 3 different conv layers in the first step via:
conv1 = nn.Conv2d(in_channels=1, out_channels=2, kernel_size=(2, 5))
conv1 = nn.Conv2d(in_channels=1, out_channels=2, kernel_size=(3, 5))
conv1 = nn.Conv2d(in_channels=1, out_channels=2, kernel_size=(4, 5))
After applying these conv layers, you could pass the outputs through the pooling layers and concatenate the the final features as given in the figure.
Note that your first figure indicates that no padding is used and thus the output activation would be smaller, while your current 3x3 filter approach is using a padding value of 1, since the feature tensor has the same number of rows.
Thank you @ptrblck,
The final implemented model is doing great. Check it out:
class CNNSentenceEncoder(nn.Module):
"""Represents a text as a dense vector."""
def __init__(self, vocabulary_size, representation_size, out_channels, kernel_sizes, sentence_length):
"""
:param vocabulary_size: number of tokens in corpus.
:param representation_size: dense vector length.
:param out_channels: number of kernels.
:param kernel_sizes: list of kernel sizes ([2,3,5], for instance)
:param sentence_length: max number of tokens for sentences.
"""
super(CNNEncoder, self).__init__()
# embedding layer
self.embedding = nn.Embedding(
num_embeddings=vocabulary_size,
embedding_dim=representation_size
)
# convolutional layers
self.convs = nn.ModuleList([
self.get_conv_layer(representation_size, out_channels, kernel_size, sentence_length)
for kernel_size in kernel_sizes])
self.linear = nn.Linear(len(convs) * out_channels, representation_size)
def get_conv_layer(self, representation_size, out_channels, kernel_size, sentence_length):
"""
Defines a convolutional block.
"""
return nn.Sequential(
nn.Conv1d(in_channels=representation_size, out_channels=out_channels, kernel_size=kernel_size),
nn.ReLU(),
nn.MaxPool1d(sentence_length - kernel_size + 1, stride=1),
nn.BatchNorm1d(out_channels)
)
def forward(self, x):
r1 = self.embedding(x)
r1 = torch.transpose(r1, 2, 1)
conv_outputs = []
for conv in self.convs:
conv_outputs.append(conv(r1))
# concatenates the outputs from each convolutional layer
cat = torch.cat(conv_outputs, 1)
# flatten
flatten_cat = torch.flatten(cat, start_dim=1)
return self.linear(flatten_cat)