With this new image I think my objective becomes clearer:
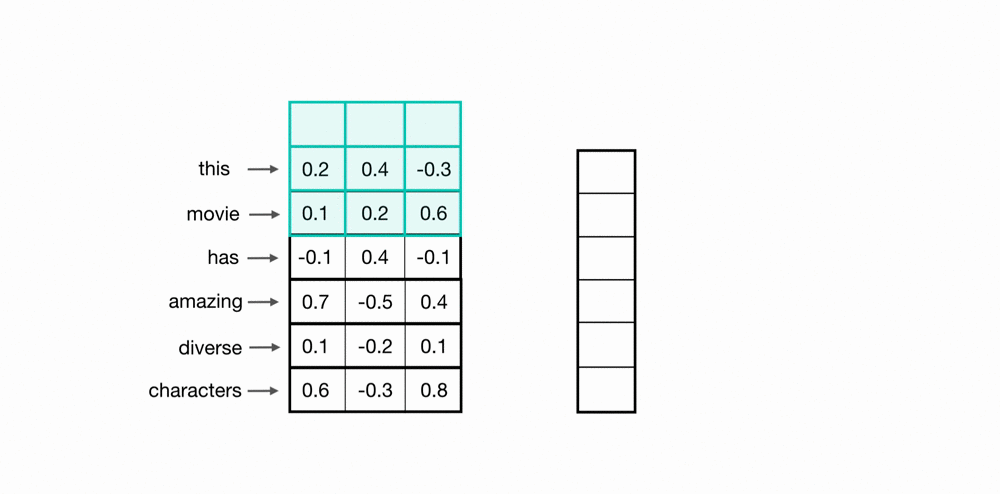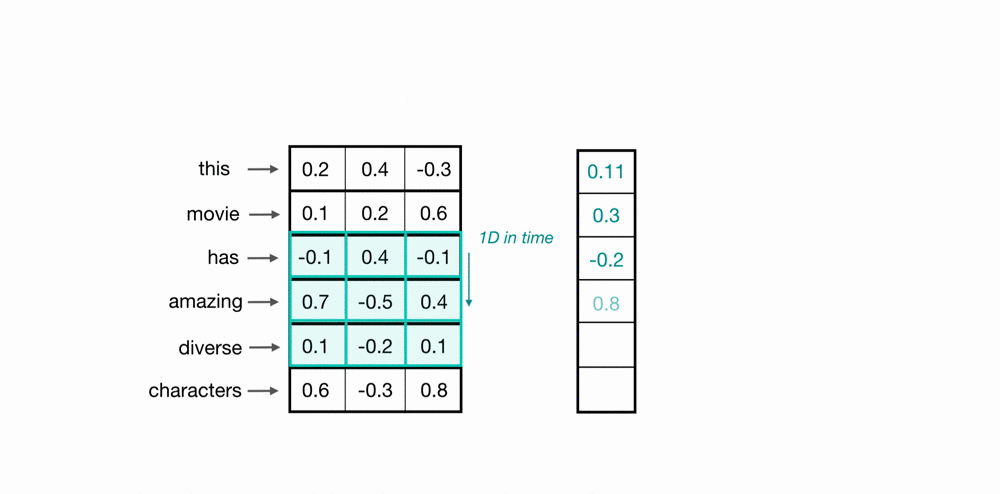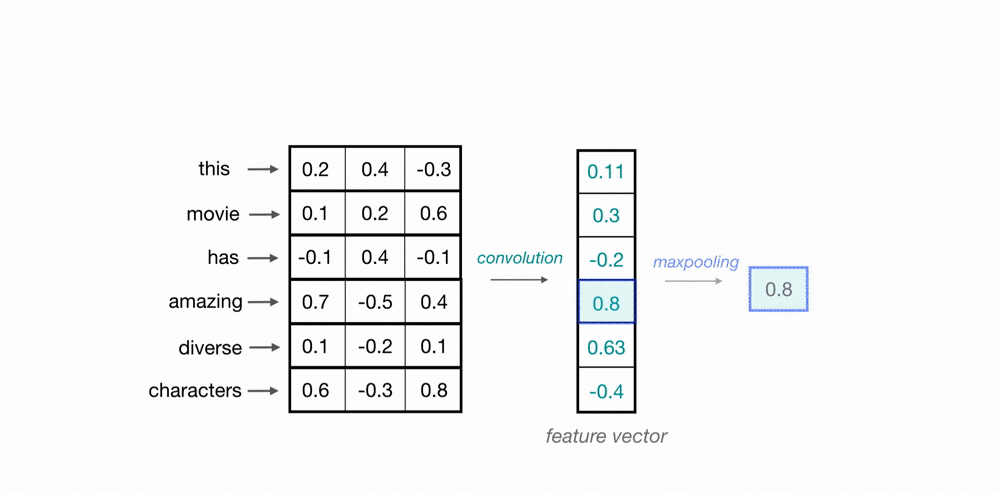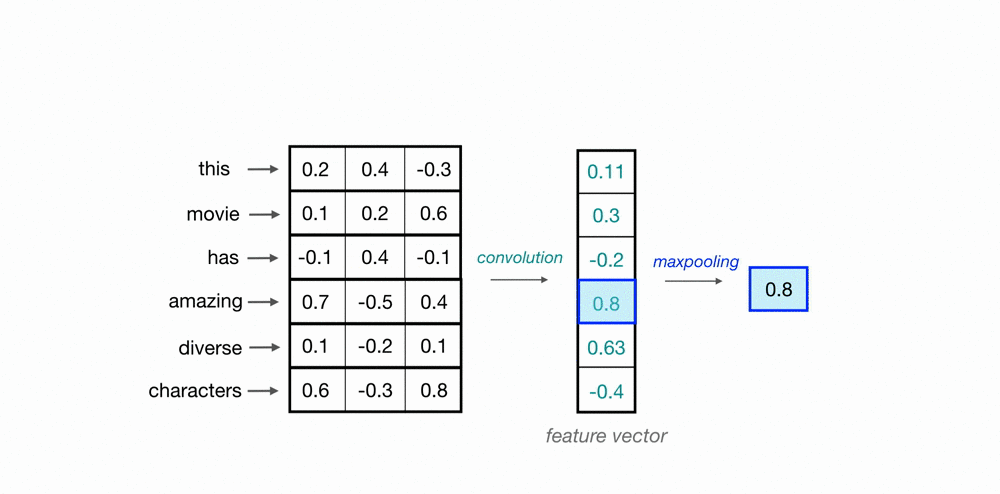
The filters/kernels are like a sliding window of different sizes. In the previous image, there are 2 filters of shape [2, 5], 2 filters of shape [3, 5], and other 2 filters of shape [4, 5].
For now, the model has only one embedding layer:
# batch of 3 sentences
input = torch.tensor(
[
[1, 2, 0, 0], # tokenized sentence 1
[3, 4, 5, 6], # tokenized sentence 2
[7, 0, 0, 0] # tokenized sentence 3
]
)
embedding_layer = torch.nn.Embedding(num_embeddings = 8, # vocabulary size
embedding_dim=5, # representation size
)
emb_out = embedding_layer(input) # torch.Size([3, 4, 5]) (batch_size, sentence_size, representation_size)
conv = torch.nn.Conv1d(in_channels=?,out_channels=?, kernel_size=?)
and, what I need to know is then, how to pass the embedding layer output into the convolutional layer as shown in the figure above.
Thanks in advance.