I’m trying to replicate the work of autoencoders which train in two phases. A good example is USAD which constructs loss values as:
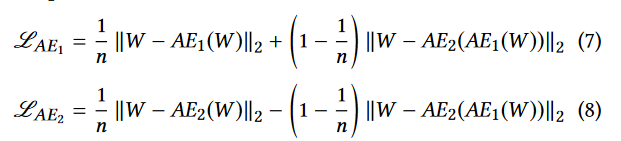
Or perhaps more usefully:
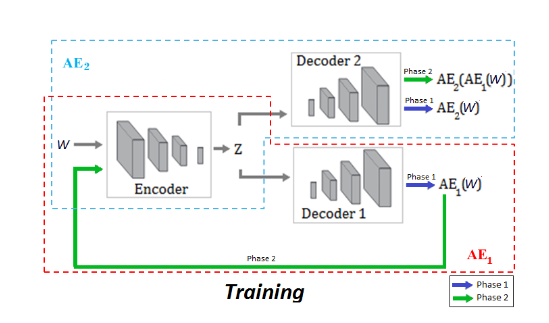
My perhaps naive PyTorch question is:
For a network like this, do you pass the losses backwards to update the weights in one go (i.e. sum the above losses into one value), or do you need to do something special to apply the updates to the separate decoders?
My thinking is that, simply summing these two loss values before passing them backward will cancel out the second term in both loss calculations. But perhaps I am missing the finer details of how the constructed gradient tree doesn’t work like that?
Any help on the matter would be greatly appreciated, thanks everyone!