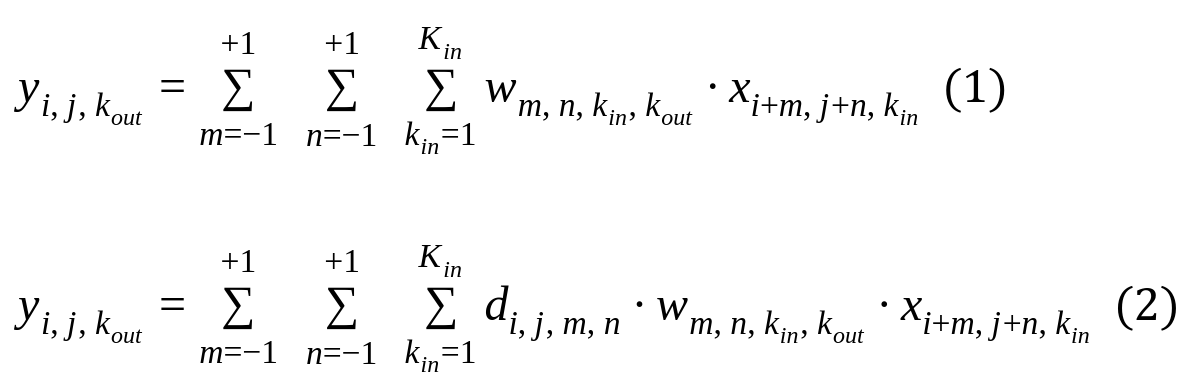Math generally is less ambiguous than words so let me just show some equations of what I’m trying to implement. (1) is standard 2D convolution with unit batch size, 3x3 kernel size, and unit stride, and (2) is what I want to implement.
In equation (2), the kernel w is modulated via element-wise product by another tensor d whose values depend on both the spatial index (i, j) as well as the dummy “convolution index” (m, n). Note that the convolutional kernel w is learnable while the modulating tensor d is known. Another way to formulate this is to use d and w to form a new kernel of shape (3, 3, H, W, K_in, K_out) whose values depend not just on the convolution index (m, n) but also on the spatial index (i, j).
Is there a simple way to express this computation without rewriting the CUDA kernels for conv2d?
I’ve been trying to implement a Gaussian-like filter where the spread of each Gaussian depends on the intensity of the actual image pixel. In other words: If the pixel intensity is close to 0, the pixel shouldn’t blur, if the value is large (close to 1) it should blur a lot.
Creating the Gaussian kernel for each image pixel is simple, but I haven’t managed to find a way to combine my kernels with the unfolded image in a similar way as it was done in the example above.