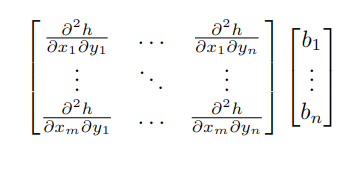I am currently trying to find the product of a 2nd order cross-derivative matrix and a vector. That is, (similar to a hessian-vector product) I want to find
for arbitrary b and h some function.
Additionally, I want to do this in a way which doesn’t ever store the matrix directly, rather I just need the product (E.g. I don’t want to use torch.func.hessian(self.h, argnums=(0, 1))).
Here is my current attempt with a toy function h:
import torch
def h(x, y):
return x**2 @ y + y**2 @ x
x = torch.tensor([1., 2., 3.], requires_grad=True)
y = torch.tensor([2., 3., 4.], requires_grad=True)
b = torch.tensor([1., 10., 100.,])
eval = h(x, y)
eval.backward()
eval_2 = (x.grad * b).sum()
eval_2.backward()
print(y.grad)
However I seem to get the following error:
RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
The short answer is that you when you use autograd to compute a second derivative,
you need to use create_graph = True so that the first derivative you compute has
a computation graph through which you can backpropagate.
Here is a script that illustrates this both with .backward() and autograd.grad():
import torch
print (torch.__version__)
def h(x, y):
return x**2 @ y + y**2 @ x
x = torch.tensor([1., 2., 3.], requires_grad=True)
y = torch.tensor([2., 3., 4.], requires_grad=True)
b = torch.tensor([1., 10., 100.,])
# first version -- doesn't work
eval = h (x, y)
eval.backward() # doesn't create computation graph for x.grad
print ('x.grad.requires_grad:', x.grad.requires_grad)
eval_2 = (x.grad * b).sum()
print ('eval_2.requires_grad:', eval_2.requires_grad)
# eval_2.backward() # fails -- no computation graph for eval_2
x.grad = None
y.grad = None
# fixed version
eval = h (x, y)
eval.backward (create_graph = True) # creates computation graph for x.grad
y.grad = None # zero out unwanted d_eval / d_y
eval_2 = (x.grad * b).sum()
eval_2.backward()
print ('y.grad:', y.grad)
x.grad = None
y.grad = None
# autograd.grad version -- a little cleaner
eval = h (x, y)
x_grad = torch.autograd.grad (eval, x, create_graph = True)[0]
y_grad = torch.autograd.grad ((x_grad * b).sum(), y)[0]
print ('y_grad:', y_grad)
And here is its output:
2.3.0
x.grad.requires_grad: False
eval_2.requires_grad: False
<path_to_pytorch_install>\torch\autograd\graph.py:744: UserWarning: Using backward() with create_graph=True will create a reference cycle between the parameter and its gradient which can cause a memory leak. We recommend using autograd.grad when creating the graph to avoid this. If you have to use this function, make sure to reset the .grad fields of your parameters to None after use to break the cycle and avoid the leak. (Triggered internally at C:\cb\pytorch_1000000000000\work\torch\csrc\autograd\engine.cpp:1208.)
return Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
y.grad: tensor([ 6., 100., 1400.])
y_grad: tensor([ 6., 100., 1400.])