Hi,
I am trying to retrain a 3D CNN model from a research article and I run into overfitting issues even upon implementing data augmentation on the fly to avoid overfitting.
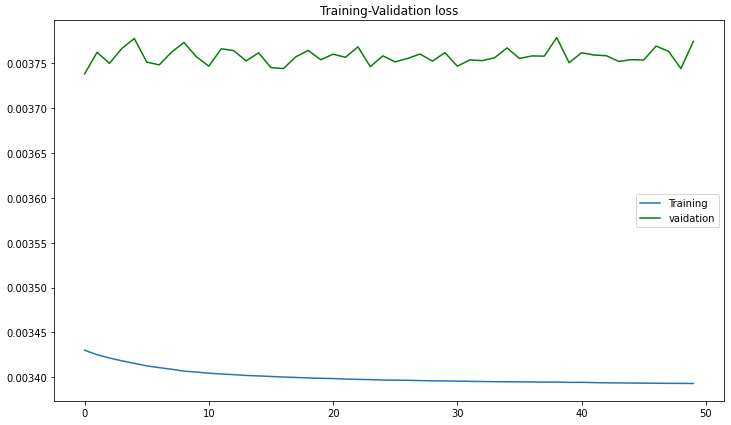
I can see that my model learns and then starts to oscillate along the same loss numbers.
Any suggestions on how to improve or how I should proceed in preventing the model from overfitting will be of great help. For further reference, I am posting my code below and the loss. Thanks
What I tried to avoid overfitting:
- image augmentation,
- regularization.
- Dropout layers
- Increasing the batch size
- Shuffling the data-loader
Training dataset size: approx 358 images+augmentation(every epoch)
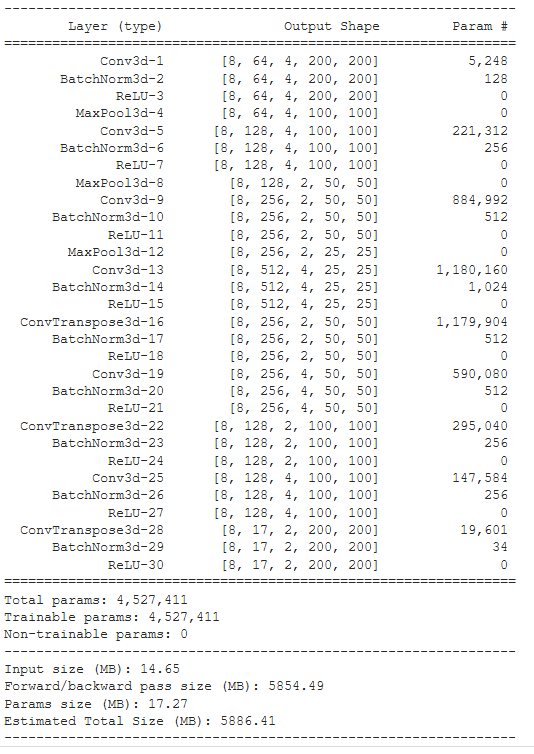
class T_LEAP(torch.nn.Module):
"""T_LEAP ARCHITECTURE"""
def __init__(self):
super(T_LEAP, self).__init__()
self.encoder = torch.nn.Sequential(
torch.nn.Conv3d(3, 64, kernel_size=(3,3,3), stride=(1,1,1), padding=(1,1,1)),
torch.nn.BatchNorm3d(num_features=64),
torch.nn.ReLU(inplace=True),
torch.nn.MaxPool3d(kernel_size=(1,2,2),stride=(1,2,2)),
torch.nn.Conv3d(64, 128, kernel_size=(3,3,3), stride=(1,1,1), padding=(1,1,1)),
torch.nn.BatchNorm3d(num_features=128),
torch.nn.ReLU(inplace=True),
torch.nn.MaxPool3d(kernel_size=(2,2,2),stride=(2,2,2)),
torch.nn.Conv3d(128, 256, kernel_size=(3,3,3), stride=(1,1,1), padding=(1,1,1)),
torch.nn.BatchNorm3d(num_features=256),
torch.nn.ReLU(inplace=True),
torch.nn.MaxPool3d(kernel_size=(1,2,2),stride=(1,2,2)),
torch.nn.Conv3d(256, 512, kernel_size=(1,3,3), stride=(1,1,1), padding=(1,1,1)),
torch.nn.BatchNorm3d(num_features=512),
torch.nn.ReLU(inplace=True),
)
self.decoder = torch.nn.Sequential(
torch.nn.ConvTranspose3d(512, 256, kernel_size=(1,3,3), stride = (1,2,2), padding=(1,1,1), output_padding=(0,1,1)),
torch.nn.BatchNorm3d(num_features=256),
torch.nn.ReLU(inplace=True),
torch.nn.Conv3d(256, 256, kernel_size=(1,3,3), stride=(1,1,1), padding=(1,1,1)),
torch.nn.BatchNorm3d(num_features=256),
torch.nn.ReLU(inplace=True),
torch.nn.ConvTranspose3d(256,128, kernel_size=(1,3,3), stride = (1,2,2), padding=(1,1,1),output_padding=(0,1,1)),
torch.nn.BatchNorm3d(num_features=128),
torch.nn.ReLU(inplace=True),
torch.nn.Conv3d(128, 128, kernel_size=(1,3,3), stride=(1,1,1), padding=(1,1,1)),
torch.nn.BatchNorm3d(num_features=128),
torch.nn.ReLU(inplace=True),
torch.nn.ConvTranspose3d(128,17, kernel_size=(1,3,3), stride = (1,2,2), padding=(1,1,1),output_padding=(0,1,1)),
torch.nn.BatchNorm3d(num_features=17),
torch.nn.ReLU(inplace=True),
)
def forward(self, image):
"""PUTTING THE MODEL TOGETHER"""
encoder = self.encoder(image)
decoder = self.decoder(encoder)
out = torch.nn.Softmax(dim=1)(decoder)
return out
model = T_LEAP()
if torch.cuda.is_available():
input = torch.rand(1,3, 2, 200, 200).cuda()
model = model.cuda()
print(model(input).shape)
else:
summary(model,
input_size=(3, 2, 200, 200),
batch_size=1
)
Training loss:

other stuff i checked:

Training loop:
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
EPOCHS = 35
lr = 1e-3
model = T_LEAP()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
model = model.to(DEVICE)
criterion = torch.nn.MSELoss()
train_loss = []
for epoch in range(EPOCHS):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
# Get[inputs, labels]
inputs, labels = data["images"], data["heatmaps"]
inputs = inputs.permute(0,2,1,3,4).to(DEVICE,dtype=torch.float)
labels = labels.unsqueeze(0).permute(1,4,0,2,3).to(DEVICE,dtype=torch.float)
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print("loss:",running_loss/len(train_loader))
train_loss.append(running_loss)
print('Finished Training')