I try to implement a depthwise separable convolution as described in the Xception paper for 3D input data (batch size, channels, x, y, z). Is the following class correct or am I missing something?
I think it might be necessary to additionally add a parameter for the number of kernels according to this example. But what would the number of kernels be then? I could not read something about this in the paper.
Hi, depthwise separable convolution is used instead of ordinary convolution. In your code you just take ordinary convolution using Conv3d plus pointwise convolution. Unique feature of depthwise convolution is work on channels separately (1 filter = 1 input channel), but ordinary convolution processes all channels (1 filter = information from all input layers)
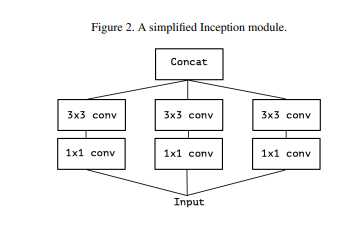
“A [2d] convolution layer attempts to learn filters in a 3D space, with 2 spatial dimensions (width and height) and a channel dimension; thus a single convolution kernel is tasked with simultaneously mapping cross-channel correlations and spatial correlations.” emphasis mine
They just mean a Conv2d with 3x3 and stride of 1, followed by 1x1 and stride of 1.
In the above case, you’d set the groups argument to 3. For example: