I’m doing research at audio technology. But I have happened to utilize CNN to classify sounds.
I have 8000 audio samples with 4 labels for each. Each label is just a float number.
I want to build a model to classify the new audio for which the labels belongs.
How can I create a CNN and predict the 4 multiple labels as output? What kind of layers do I need?
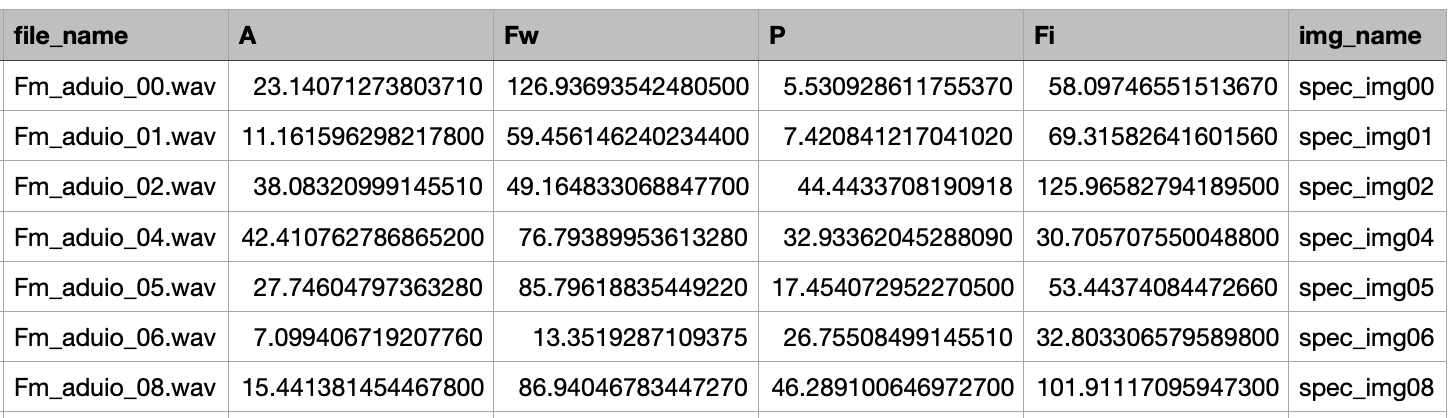
The image spectra are based on those 4 parameters: A, Fw, P, and Fi. The generated audio samples iare produced through a group of algorithm, but each time we only choose one underlying algorithm. So any trained model is a reflection of that algorithm.
My working flow is: audio → spectrum → training model → evaluating.
At the end, I want to create a model which can predict a new audio sample generated by the same algorithm.
Are the labels discrete classes or intended to be continuous values? In either case you likely do not need to do anything special as a first attempt using a standard classification back bone as they will output continuous logits by default. For a multilabel objective you could use e.g., BCEWithLogitsLoss — PyTorch 1.11.0 documentation and for a regression objective you could use e.g., MSELoss — PyTorch 1.11.0 documentation
Hello eqy,
Thanks for your very early response to me.
In this project, the audio samples have been transformed to spectra. Actually, each audio is generated by a group of algorithms where the 4 labels are the factors.
So, I wish I could build a CNN and feed the trained model with a new bunch of audio and hope the model could give the predictions(4 labels in float) back for me.
The 4 labels for each audio and according spectrum are randomly generated.
The first layer of the model should be conv2d, and so on. But how can I define the last linear lawyer as the labels are randomly generated. On the control, if we are training a speech audio, our labels is easy as [yes, no, cat, dog]. But in my case, the labels are unpredictable.
So, can you give a a simple demo to address the model?
I’m a bit confused here, could you give an example of what the randomly generated labels would look like? If they are actually “unpredictable,” then I’m wondering if it would make sense to frame it as a learning task?
First, I use a group of algorithms to generate the audio samples but each time a certain algorithm. So the trained model should be the reflection of that algorithm.
Next, the 4 labels are randomly selected within a given range, and then the audio samples are based on those 4 labels and the algorithm.
So, what I want to implement is to create a model and feed the trained model a new audio sample generated by the same selected algorithm, and hope the model give me the prediction(4 labels) back.
How can I define the CNN model class and implement the forward function?
Please take a look at the MNIST and ImageNet examples linked above for a recipe involving defining your own model or using a preexisting architecture.
From the table linked it looks like the labels are “continuous,” so you might want to start off with MSE and tune things from there (e.g., normalizing the labels etc. if they are varied in scale, etc.).
Oh, that’s good.
But in my case, the labels are digits generated randomly from a given range, like [20, 50] or so.
I looked at the MNIST example, and torch.nn.CrossEntropyLoss() was used.
I used the same loss function as well, but have several runtime errors.
So,
What loss function do you suggest?
How can I define my output layer since there are uncountable outputs in theory. It’s not simply going down on 2 or 3 categories. The output labels should be a random guess from the same range.