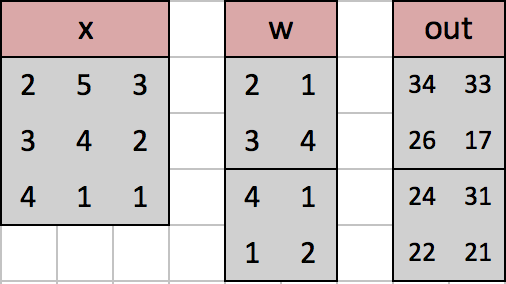
Hello, I’m new to pytorch and I’d like to start with small steps by reproducing the following conv2d example found here.
I would like to correctly implement the convolution of one image of size MxNx1 with c number of filters with size mxnx1. I suppose stacking filters into one filter tensor of size mxnxc, with the right reshaping, should produce stacked convolved images with last dimension of c and spatial dimensions depending on strides and convention (full, equal or valid).
Thank you, this really boosted me up. Since I don’t intend to build any neural network model, are there anything to worry about gradients or any unwanted calculations? My image is of the order 1e4x1e4, while kernels are of the order 500x500 - 100x100, and I only need to do some mathematical preprocessing after convolving. Among such operations I’d have to interpolate the convolved tensor along an arbitrary path (a large number of random paths, instead of one only) as found here. I expect lifting this up to fully tensor notation using pytorch should not be that difficult. The convolution part I tested on a server with 80 cpus and 512 GB, and it works like a charm, much faster when compared to scipy and numpy and slightly outperforms tensorflow.
No, you wouldn’t need to care about gradients etc. as in my example I did not initialize the weight tensor as a trainable nn.Parameter and also didn’t set its requires_grad attribute to True so that Autograd will ignore it and won’t save any intermediates needed for the gradient calculation.