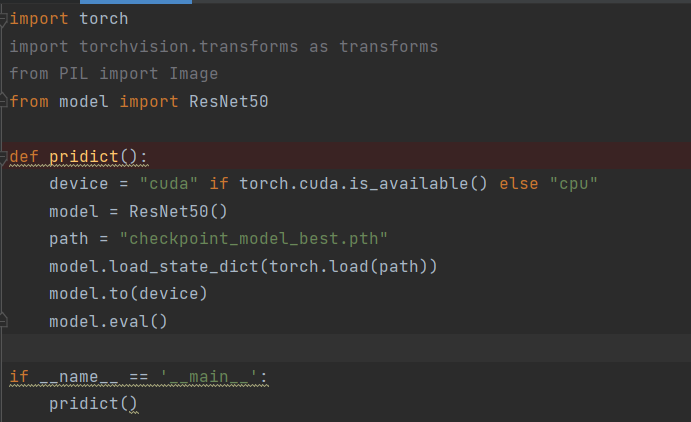
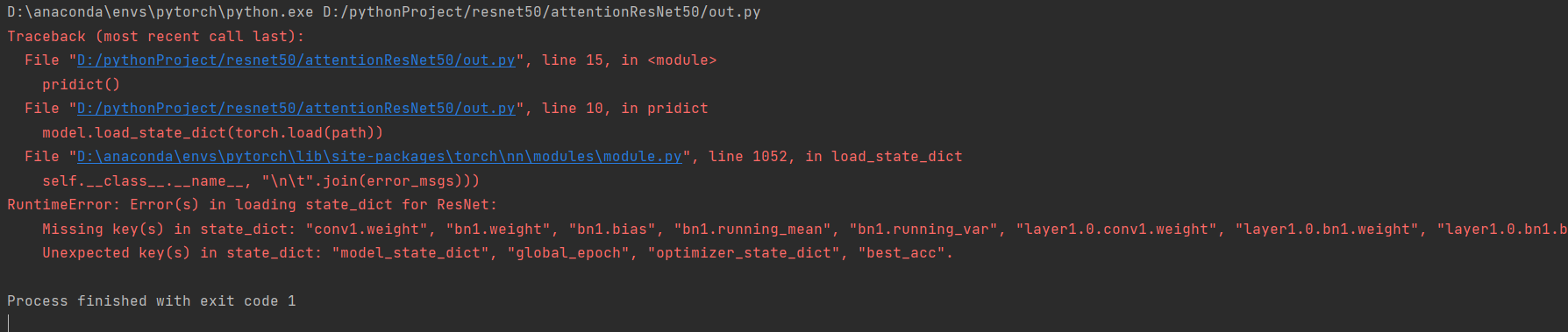
i see. I should add from model import A
then model = A()? But I can’t find a function whose return value is model…Could you please guide me when you are free.
Here is my model file:
import torch
import torch.nn as nn
import torch.nn.functional as F
def get_n_params(model):
pp=0
for p in list(model.parameters()):
nn=1
for s in list(p.size()):
nn = nn*s
pp += nn
return pp
class MHSA(nn.Module):
def init(self, n_dims, width=14, height=14, heads=4):
super(MHSA, self).init()
self.heads = heads
self.query = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.key = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.value = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.rel_h = nn.Parameter(torch.randn([1, heads, n_dims // heads, 1, height]), requires_grad=True)
self.rel_w = nn.Parameter(torch.randn([1, heads, n_dims // heads, width, 1]), requires_grad=True)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
n_batch, C, width, height = x.size()
q = self.query(x).view(n_batch, self.heads, C // self.heads, -1)
k = self.key(x).view(n_batch, self.heads, C // self.heads, -1)
v = self.value(x).view(n_batch, self.heads, C // self.heads, -1)
content_content = torch.matmul(q.permute(0, 1, 3, 2), k)
content_position = (self.rel_h + self.rel_w).view(1, self.heads, C // self.heads, -1).permute(0, 1, 3, 2)
content_position = torch.matmul(content_position, q)
energy = content_content + content_position
attention = self.softmax(energy)
out = torch.matmul(v, attention.permute(0, 1, 3, 2))
out = out.view(n_batch, C, width, height)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_planes, planes, stride=1, heads=4, mhsa=False, resolution=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
if not mhsa:
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, padding=1, stride=stride, bias=False)
else:
self.conv2 = nn.ModuleList()
self.conv2.append(MHSA(planes, width=int(resolution[0]), height=int(resolution[1]), heads=heads))
if stride == 2:
self.conv2.append(nn.AvgPool2d(2, 2))
self.conv2 = nn.Sequential(*self.conv2)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, self.expansion * planes, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(self.expansion * planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride),
nn.BatchNorm2d(self.expansion*planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
out += self.shortcut(x)
out = F.relu(out)
return out
reference
class ResNet(nn.Module):
def init(self, block, num_blocks, num_classes=5, resolution=(224, 224), heads=4):
super(ResNet, self).init()
self.in_planes = 64
self.resolution = list(resolution)
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
# self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
if self.conv1.stride[0] == 2:
self.resolution[0] /= 2
if self.conv1.stride[1] == 2:
self.resolution[1] /= 2
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # for ImageNet
if self.maxpool.stride == 2:
self.resolution[0] /= 2
self.resolution[1] /= 2
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2, heads=heads, mhsa=True)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Sequential(
nn.Dropout(0.3), # All architecture deeper than ResNet-200 dropout_rate: 0.2
nn.Linear(512 * block.expansion, num_classes)
)
def _make_layer(self, block, planes, num_blocks, stride=1, heads=4, mhsa=False):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for idx, stride in enumerate(strides):
layers.append(block(self.in_planes, planes, stride, heads, mhsa, self.resolution))
if stride == 2:
self.resolution[0] /= 2
self.resolution[1] /= 2
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
out = self.relu(self.bn1(self.conv1(x)))
out = self.maxpool(out) # for ImageNet
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.avgpool(out)
out = torch.flatten(out, 1)
out = self.fc(out)
return out
def ResNet50(num_classes=5, resolution=(256, 256), heads=4):
return ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, resolution=resolution, heads=heads)
def main():
x = torch.randn([2, 3, 256, 256])
model = ResNet50(resolution=tuple(x.shape[2:]), heads=8)
print(model(x).size())
print(get_n_params(model))
if name == ‘main’:
main()
Another file that you may need, just in case(main.py):
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import os
from config import load_config
from preprocess import load_data
from model import ResNet50
def save_checkpoint(best_acc, model, optimizer, args, epoch):
print(‘Best Model Saving…’)
if args.device_num > 1:
model_state_dict = model.module.state_dict()
else:
model_state_dict = model.state_dict()
torch.save({
'model_state_dict': model_state_dict,
'global_epoch': epoch,
'optimizer_state_dict': optimizer.state_dict(),
'best_acc': best_acc,
}, os.path.join('checkpoints', 'checkpoint_model_best.pth'))
def _train(epoch, train_loader, model, optimizer, criterion, args):
model.train()
losses = 0.
acc = 0.
total = 0.
for idx, (data, target) in enumerate(train_loader):
if args.cuda:
data, target = data.cuda(), target.cuda()
output = model(data)
_, pred = F.softmax(output, dim=-1).max(1)
acc += pred.eq(target).sum().item()
total += target.size(0)
optimizer.zero_grad()
loss = criterion(output, target)
losses += loss
loss.backward()
if args.gradient_clip > 0:
torch.nn.utils.clip_grad_norm_(model.parameters(), args.gradient_clip)
optimizer.step()
if idx % args.print_intervals == 0 and idx != 0:
print('[Epoch: {0:4d}], Loss: {1:.3f}, Acc: {2:.3f}, Correct {3} / Total {4}'.format(epoch,
losses / (idx + 1),
acc / total * 100.,
acc, total))
def _eval(epoch, test_loader, model, args):
model.eval()
acc = 0.
with torch.no_grad():
for data, target in test_loader:
if args.cuda:
data, target = data.cuda(), target.cuda()
output = model(data)
_, pred = F.softmax(output, dim=-1).max(1)
acc += pred.eq(target).sum().item()
print('[Epoch: {0:4d}], Acc: {1:.3f}'.format(epoch, acc / len(test_loader.dataset) * 100.))
return acc / len(test_loader.dataset) * 100.
def main(args):
train_loader, test_loader = load_data(args)
model = ResNet50()
optimizer = optim.SGD(model.parameters(), lr=args.lr, weight_decay=args.weight_decay, momentum=args.momentum)
if not os.path.isdir('checkpoints'):
os.mkdir('checkpoints')
if args.checkpoints is not None:
checkpoints = torch.load(os.path.join('checkpoints', args.checkpoints))
model.load_state_dict(checkpoints['model_state_dict'])
optimizer.load_state_dict(checkpoints['optimizer_state_dict'])
start_epoch = checkpoints['global_epoch']
else:
start_epoch = 1
if args.cuda:
model = model.cuda()
if not args.evaluation:
criterion = nn.CrossEntropyLoss()
lr_scheduler = optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=10, T_mult=2, eta_min=0.0001)
global_acc = 0.
for epoch in range(start_epoch, args.epochs + 1):
_train(epoch, train_loader, model, optimizer, criterion, args)
best_acc = _eval(epoch, test_loader, model, args)
if global_acc < best_acc:
global_acc = best_acc
save_checkpoint(best_acc, model, optimizer, args, epoch)
lr_scheduler.step()
print('Current Learning Rate: {}'.format(lr_scheduler.get_last_lr()))
else:
_eval(start_epoch, test_loader, model, args)
if name == ‘main’:
args = load_config()
main(args)
Thank you sincerely