Hello!
I’m working on a task of binary classification.
I use Dropout and BatchNormalization layers in my network. So I use net.train(False) to evaluate my network.
However, I find something strange when I try to calculate the accuracy.
After training, I set net.train(False). And I find the accuracy on train batches is around 80% despite that the loss was very low.
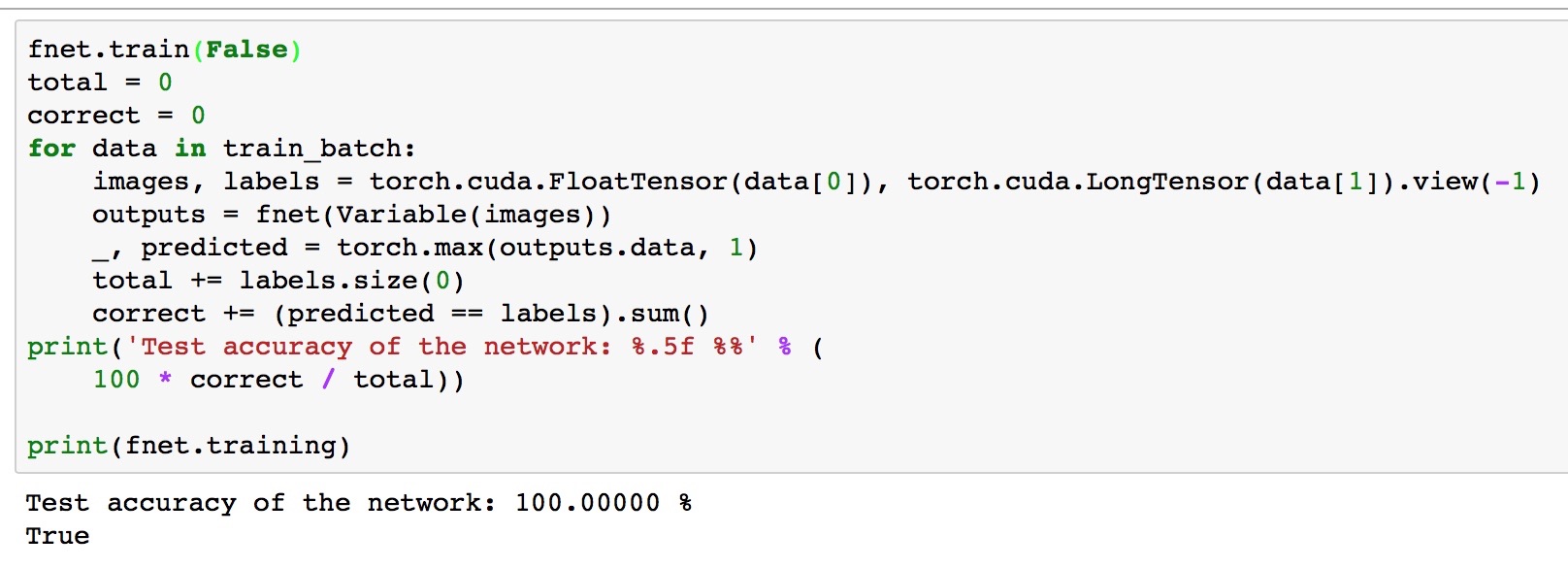
Then I change it to net.train(True), and the accuracy on train batches rose to nearly 100%.
After that, I change it back to net.train(False). And surprisingly, the accuracy is still over 99%.
Can anyone explain this? It drives me crazy!
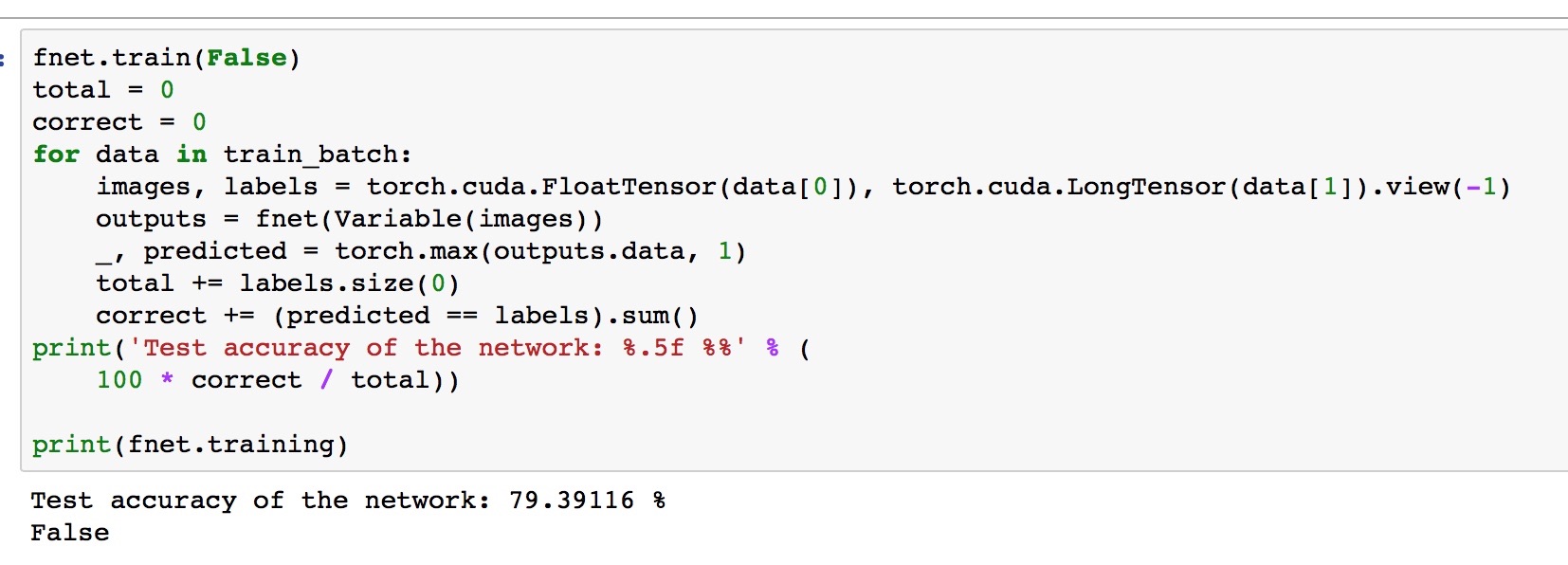
p.s. Here is my code for evaluate:
fnet.train(False)
total = 0
correct = 0
for data in train_batch:
images, labels = torch.cuda.FloatTensor(data[0]), torch.cuda.LongTensor(data[1]).view(-1)
outputs = fnet(Variable(images))
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
print(‘Test accuracy of the network: %.5f %%’ % (
100 * correct / total))
The BatchNorm layers got updated when you switched back to net.train(True) with the statistics of the test set. After calling net.train(False) again, the BatchNorm is still using the updated running_mean and running_var.
This makes sense, if your training and test set differ in their statistics.
Btw, in your code snippets you use the training data for evaluating the performance?
Doing this you will only get an estimate of your resubstitution error, which does not tell anything about the model’s performance on new unseen data.
Back to the question.
This is a known issue, if your data statistics are very shaky. You could try to increase the momentum parameter in BatchNorm layers, so that the running stats will be weighted higher.
Thanks for the correction on this and sorry for the confusion!
I misunderstood the documentation saying
momentum – the value used for the running_mean and running_var computation.
Sounds like momentum is the value used to scale the so far accumulated running_* params.
With a default value of 0.1 my understanding doesn’t really make sense though.