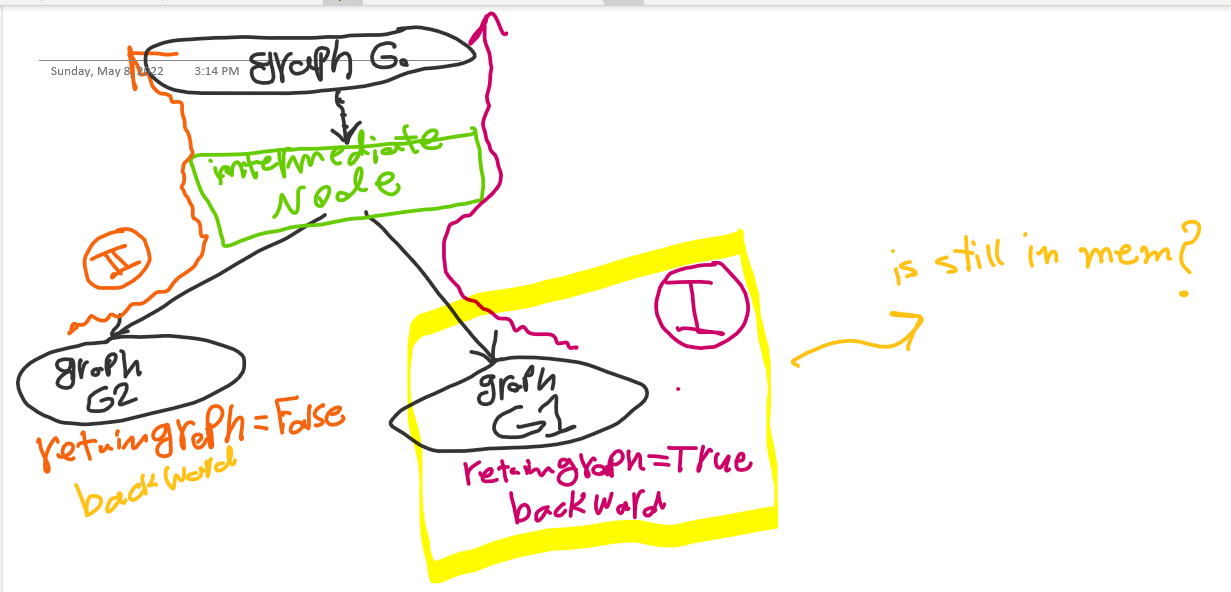
This image shows my computational graph(Something like a DCGAN). And I first call backward on the last intermediate node of G1 with retain_graph=true. And then call backward on the last intermediate node of G2 with retain_graph=false.
My question is graph G1 still in memory?
I want to train my network in N epochs. How many G1 graphs are still in memory?
When the values all go out of scope and are collected, the autograd graph should be released, too.
That said: If you are concerned about it and you cannot do a joint backward, you could manually split the graph (with intermediate_new = intermediate.detach().requires_grad(), use that in your computation and then do the first backward and do intermediate.backward(intermediate_new.grad, retain_graph=True).