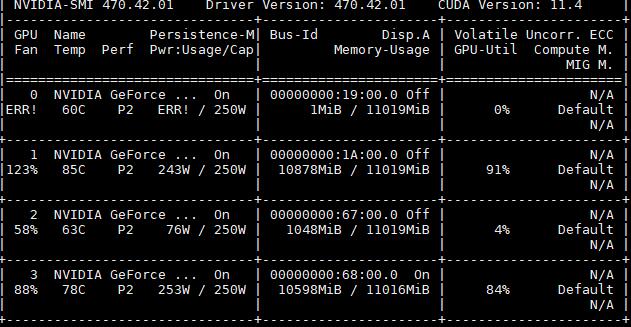
My computer has 4 GPUs, they are all NVIDIA GeForce 2080TI, my environment is:
NVIDIA-SMI 470.42.01 Driver Version: 470.42.01 CUDA Version: 11.4.20210623 cuDNN Version: 8.2.4.15-1+cuda11.4 pytorch Version: 1.7.0
The same code runs on the 1st and 3rd GPU and everything works fine with pytorch, but there are different errors on GPU 0 and 2.
When using CUDA_VISIBLE_DEVICES=0:I usually connect the screen to GPU 0 for display, and when it is running, I always closed the visual interface. It reported when running:
/pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [43,0,0], thread: [32,0,0] Assertion
idx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed.
/pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [43,0,0], thread: [33,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed.
/pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [43,0,0], thread: [34,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed.
/pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:115: operator(): block: [43,0,0], thread: [35,0,0] Assertionidx_dim >= 0 && idx_dim < index_size && "index out of bounds"failed.
…
Traceback (most recent call last):
…
File “/home/Project/test.py”, line 47, in get_rate_eachc
_, inverse, counts = torch.unique(CH_area[i], return_inverse=True, return_counts=True)
File “/home/wenqu/workspace/pytorch/lib/python3.6/site-packages/torch/_jit_internal.py”, line 265, in fn
return if_true(*args, **kwargs)
File “/home/wenqu/workspace/pytorch/lib/python3.6/site-packages/torch/_jit_internal.py”, line 265, in fn
return if_true(*args, **kwargs)
File “/home/wenqu/workspace/pytorch/lib/python3.6/site-packages/torch/functional.py”, line 682, in _unique_impl
return_counts=return_counts,
RuntimeError: transform: failed to synchronize: cudaErrorAssert: device-side assert triggered
When using CUDA_VISIBLE_DEVICES=0:
Traceback (most recent call last):
…
File “/home/workspace/pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py”, line 727, in _call_impl
result = self.forward(*input, **kwargs)
File “/home/Project/test2.py”, line 44, in forward
theta = self.tanh(self.conv0(x))
File “/home/workspace/pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py”, line 727, in _call_impl
result = self.forward(*input, **kwargs)
File “/home/workspace/pytorch/lib/python3.6/site-packages/torch/nn/modules/conv.py”, line 423, in forward
return self._conv_forward(input, self.weight)
File “/home/workspace/pytorch/lib/python3.6/site-packages/torch/nn/modules/conv.py”, line 420, in _conv_forward
self.padding, self.dilation, self.groups)
RuntimeError: cuDNN error: CUDNN_STATUS_INTERNAL_ERROR
You can try to repro this exception using the following code snippet. If that doesn’t trigger the error, please include your original repro script when reporting this issue.import torch
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.benchmark = True
torch.backends.cudnn.deterministic = False
torch.backends.cudnn.allow_tf32 = True
data = torch.randn([4, 3, 224, 224], dtype=torch.float, device=‘cuda’, requires_grad=True)
net = torch.nn.Conv2d(3, 128, kernel_size=[3, 3], padding=[1, 1], stride=[1, 1], dilation=[1, 1], groups=1)
net = net.cuda().float()
out = net(data)
out.backward(torch.randn_like(out))
torch.cuda.synchronize()ConvolutionParams
data_type = CUDNN_DATA_FLOAT
padding = [1, 1, 0]
stride = [1, 1, 0]
dilation = [1, 1, 0]
groups = 1
deterministic = false
allow_tf32 = true
input: TensorDescriptor 0x499d450
type = CUDNN_DATA_FLOAT
nbDims = 4
dimA = 4, 3, 224, 224,
strideA = 150528, 50176, 224, 1,
output: TensorDescriptor 0x77c4b480
type = CUDNN_DATA_FLOAT
nbDims = 4
dimA = 4, 128, 224, 224,
strideA = 6422528, 50176, 224, 1,
weight: FilterDescriptor 0x7c448fe0
type = CUDNN_DATA_FLOAT
tensor_format = CUDNN_TENSOR_NCHW
nbDims = 4
dimA = 128, 3, 3, 3,
Pointer addresses:
input: 0x7fc1ba000000
output: 0x7fc1b2000000
weight: 0x7fc2211b9000
When using CUDA_VISIBLE_DEVICES=0,1,2: Reported the same error as GPU 0.
These errors do not occur on 1,3 GPU. So I cant determine where the problem is, whether my code is wrong or the GPUs have some problems. Does anyone have the same problem?
Thx u for any help.