Anyway, thank you very much for your answer. Now my situation is a bit complicated.
On device 0,first, I was trying to fix the indexing issue with CUDA_LAUNCH_BLOCKING=1. I found it might come from torch.gather, so I tried to cancel the use of it. It worked and device 0 can training with ‘CUDA_LAUNCH_BLOCKING=1’. But after training for a while, device 0 disappeared from nvidia-smi. I used sudo nvidia-persistenced --persistence-mode to fix this issue.
By the way, I have a custom loss, maybe its gradient will be relatively large,we temporarily call it 'A loss‘’. Continue training, I found that device 0 has the following situations:
- It can training, and anything a simple network: for example, a network with only one convolutional layer and using mseloss. (Whether using MSE loss or Aloss, whether using
CUDA_LAUNCH_BLOCKING=1or not) - When using a Complex network(with resnet34 backbone and jumper connection, decoding network):
- It will report
cuDNN error: CUDNN_STATUS_INTERNAL_ERRORwhen running without usingCUDA_LAUNCH_BLOCKING=1. - When running with
CUDA_LAUNCH_BLOCKING=1, it can be trained not to ask any questions. But its loss is easy to become NAN when using Aloss.
I make a few guesses:
- On device 0, it seems to be more sensitive to large values than others. So it is more likely to cause the value to overflow and cause loss to become NAN.
- This problem may not come from pytorch but the GPU itself. Because my code does not have any problems mentioned in the above device 0 on device 1, 3.
- But I cannot understand
CUDA_LAUNCH_BLOCKING=1cannot solve the problem ofcuDNN error: CUDNN_STATUS_INTERNAL_ERROR
As for device 2, when I try to use A to solve it, it will arise Unable to find a valid cuDNN algorithm to run convolution. I carefully referred to the questions you answered:
Unable to find a valid cuDNN algorithm to run convolution
And it doesnt worked.
In the end, I found that the above two devices 0 and 2 that have problems are both when trying to train:
Their Fan and Pwr Usage will become ERR.
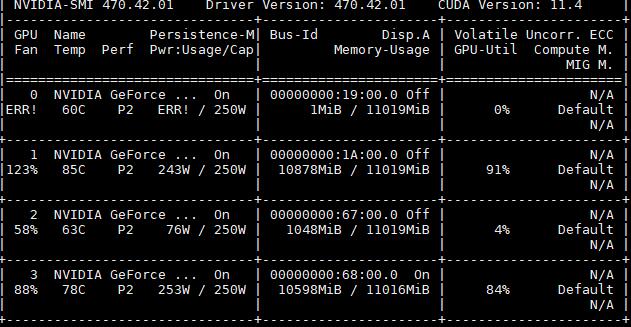
I am very grateful to your help. If you have any relevant information please help me.