I have two workstation: one with RTX 3090 and another with RTX A6000. The model on RTX 3090 takes 8897MB in total.When it runs on the RTX A6000 it takes 36945MB. I have identical cuda, cudnn and pytorch version
Is the memory allocated or only reserved in the cache?
In the latter case, more available memory could be used for e.g. the cudnn workspace to check for faster kernels and could be reused afterwards.
- torch.cuda.memory_summary()
37039898624 - torch.cuda.memory_cached()
37039898624 - torch.cuda.memory_reserved()
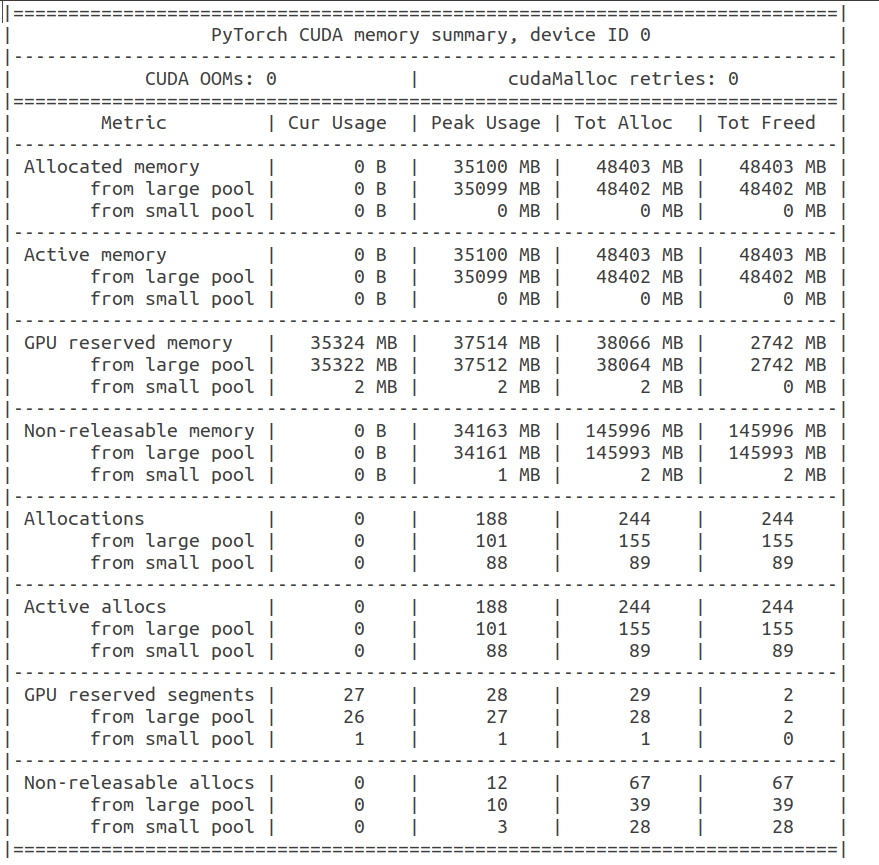
37039898624 - torch.cuda.memory_cached()
37039898624 - torch.cuda.memory_reserved()
Based on the output, no memory is allocated (only in the cache), which is a bit strange.
Did you delete all tensors before checking the memory stats?
No, i must delete the object with del and then apply torch.cuda.empty_cache()?
No, you do not have to delete anything, if it’s still used, but allocated memory should have been shown in this case as seen here:
import torch
print(torch.cuda.memory_summary())
|===========================================================================|
| PyTorch CUDA memory summary, device ID 0 |
|---------------------------------------------------------------------------|
| CUDA OOMs: 0 | cudaMalloc retries: 0 |
|===========================================================================|
| Metric | Cur Usage | Peak Usage | Tot Alloc | Tot Freed |
|---------------------------------------------------------------------------|
| Allocated memory | 0 B | 0 B | 0 B | 0 B |
| from large pool | 0 B | 0 B | 0 B | 0 B |
| from small pool | 0 B | 0 B | 0 B | 0 B |
|---------------------------------------------------------------------------|
...
x = torch.randn(1024, device='cuda')
print(torch.cuda.memory_summary())
|===========================================================================|
| PyTorch CUDA memory summary, device ID 0 |
|---------------------------------------------------------------------------|
| CUDA OOMs: 0 | cudaMalloc retries: 0 |
|===========================================================================|
| Metric | Cur Usage | Peak Usage | Tot Alloc | Tot Freed |
|---------------------------------------------------------------------------|
| Allocated memory | 4096 B | 4096 B | 4096 B | 0 B |
| from large pool | 0 B | 0 B | 0 B | 0 B |
| from small pool | 4096 B | 4096 B | 4096 B | 0 B |
|---------------------------------------------------------------------------|
| Active memory | 4096 B | 4096 B | 4096 B | 0 B |
| from large pool | 0 B | 0 B | 0 B | 0 B |
| from small pool | 4096 B | 4096 B | 4096 B | 0 B |
|---------------------------------------------------------------------------|
| GPU reserved memory | 2048 KB | 2048 KB | 2048 KB | 0 B |
| from large pool | 0 KB | 0 KB | 0 KB | 0 B |
| from small pool | 2048 KB | 2048 KB | 2048 KB | 0 B |
|---------------------------------------------------------------------------|
| Non-releasable memory | 2044 KB | 2044 KB | 2044 KB | 0 B |
| from large pool | 0 KB | 0 KB | 0 KB | 0 B |
| from small pool | 2044 KB | 2044 KB | 2044 KB | 0 B |
|---------------------------------------------------------------------------|
| Allocations | 1 | 1 | 1 | 0 |
| from large pool | 0 | 0 | 0 | 0 |
| from small pool | 1 | 1 | 1 | 0 |
|---------------------------------------------------------------------------|
| Active allocs | 1 | 1 | 1 | 0 |
| from large pool | 0 | 0 | 0 | 0 |
| from small pool | 1 | 1 | 1 | 0 |
|---------------------------------------------------------------------------|
| GPU reserved segments | 1 | 1 | 1 | 0 |
| from large pool | 0 | 0 | 0 | 0 |
| from small pool | 1 | 1 | 1 | 0 |
|---------------------------------------------------------------------------|
| Non-releasable allocs | 1 | 1 | 1 | 0 |
| from large pool | 0 | 0 | 0 | 0 |
| from small pool | 1 | 1 | 1 | 0 |
|===========================================================================|
Here you can see that the memory is initially empty and after creating a tensor with 1024 elements in float32 4096 bytes will be allocated and 2MB will be in the cache.
However, your currently allocated memory is zero, so no active tensors are on the GPU.
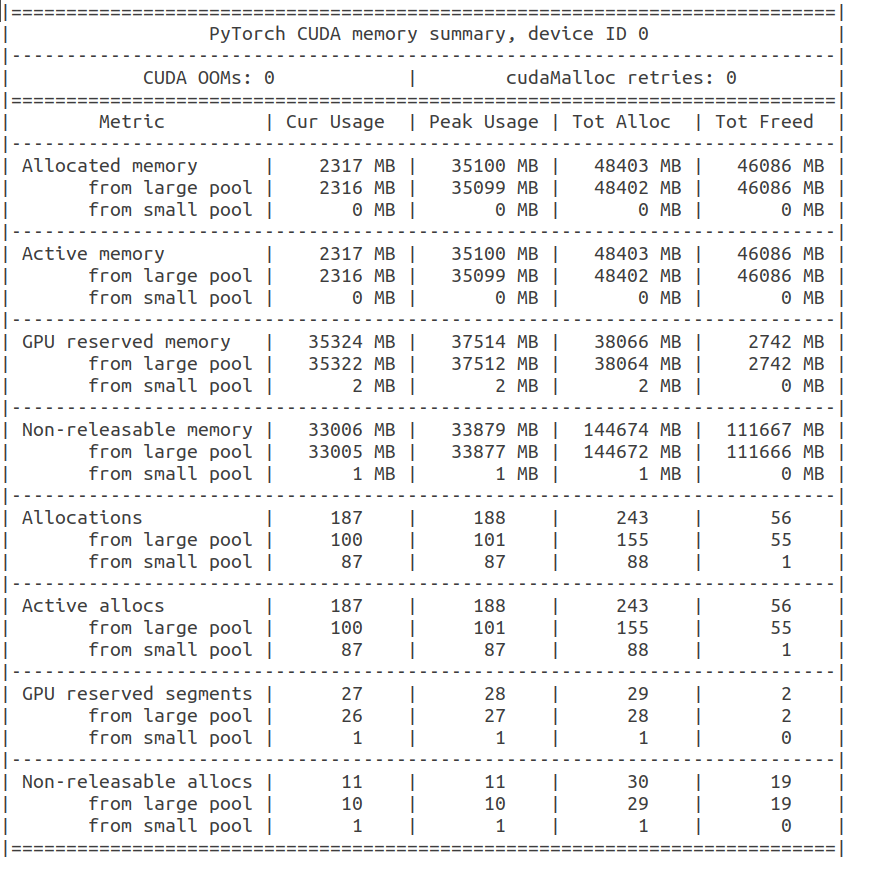
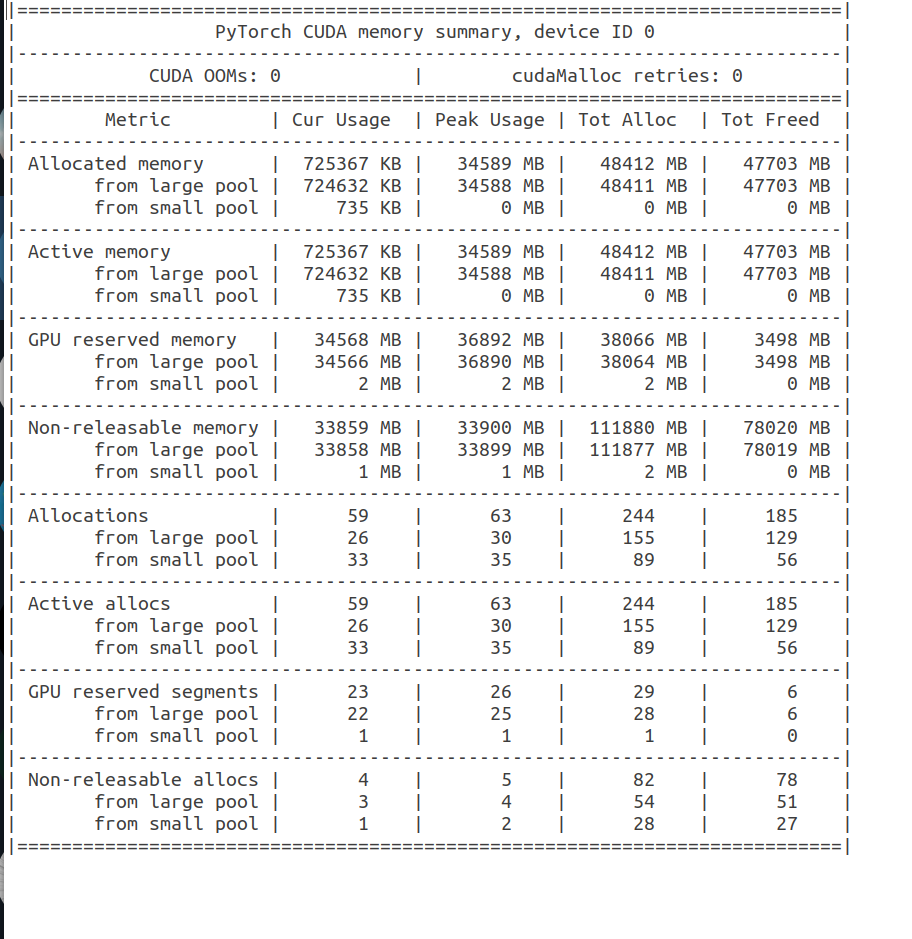
It seems to me that torch.backends.cudnn.benchmark = False solve my problem) Thank you!
1 Like