Contributing as an example of how to create a stateless gridworld environment in torchRL
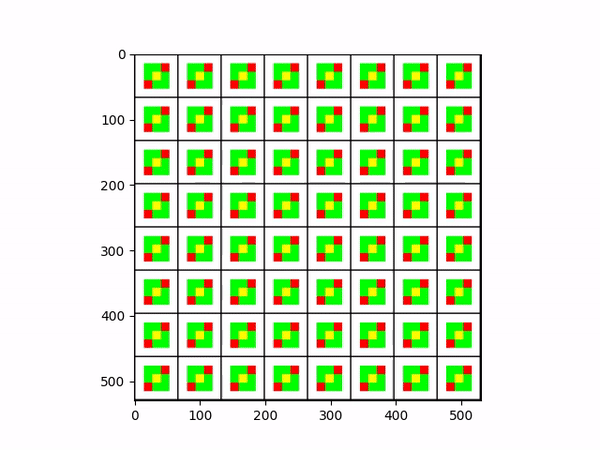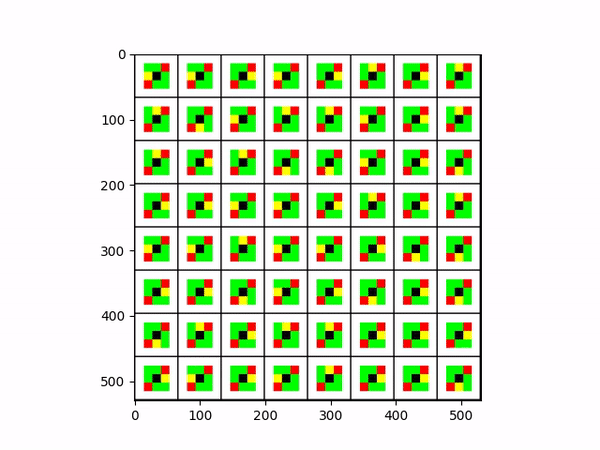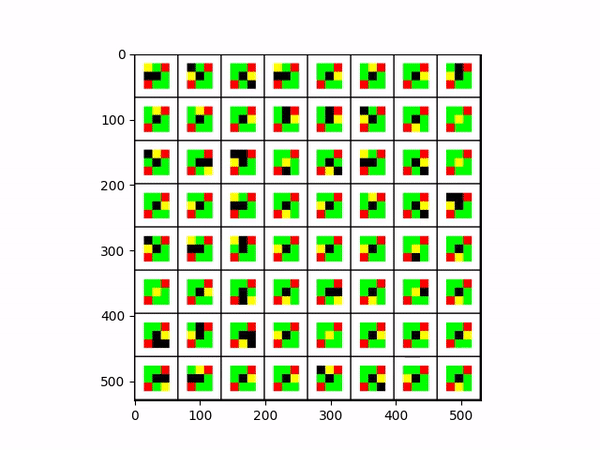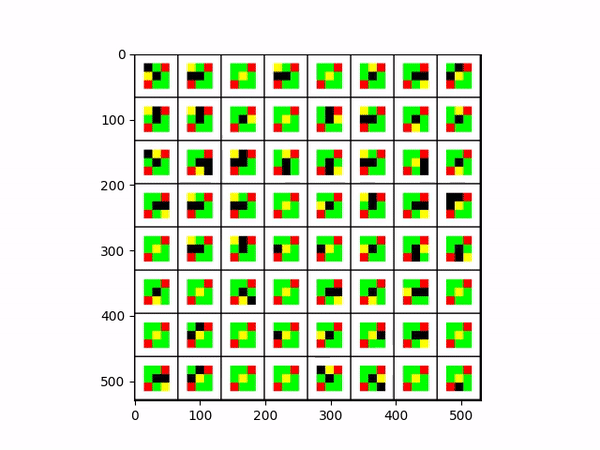
The yellow tile is the agent (player), the green tiles are rewards being picked up by the agent, the red tiles are negative rewards that return done, and the white tiles are walls.
Observation space is N, 3, 64, 64 and the Actions space is N, 4 (Discrete)
The entire environment is vectorized and can run as many gridworlds as you can fit in memory.
The environment is also stateless, so theoretically, you could tree search it… but I’ve not implemented or tested anything like that.
You can change the gridworld layout by editing the gen_params function, I think you will find it fairly intuitive ![]()
Oh, and make sure the outside of the gridworld is always walls, or the agent will go out of bounds and an exception will be thrown.
from typing import Optional
import torch
from torch import tensor
from tensordict import TensorDict
from torchrl.data import CompositeSpec, BoundedTensorSpec, UnboundedContinuousTensorSpec, UnboundedDiscreteTensorSpec, DiscreteTensorSpec, \
UnboundedContinuousTensorSpec
from torchrl.envs import (
EnvBase,
Transform,
TransformedEnv,
)
from torchrl.envs.utils import check_env_specs, step_mdp
from torchrl.envs.transforms.transforms import _apply_to_composite
from torch.nn.functional import interpolate
from torchvision.utils import make_grid
from math import prod
"""
A minimal stateless vectorized gridworld in pytorch rl
Action space: (0, 1, 2, 3) -> N, E, S, W
Features
walls
1 time pickup rewards or penalties
done tiles
outputs a fully observable RGB image
look at the gen_params function to setup the world
example of configuring and performing a rollout at bottom
Maybe I will write an even simpler stateless non-vectorized version of this gridworld
"""
# N/S is reversed as y-axis in images is reversed
action_vec = [
tensor([0, -1]), # N
tensor([1, 0]), # E
tensor([0, 1]), # S
tensor([-1, 0]) # W
]
action_vec = torch.stack(action_vec)
yellow = tensor([255, 255, 0], dtype=torch.uint8)
red = tensor([255, 0, 0], dtype=torch.uint8)
green = tensor([0, 255, 0], dtype=torch.uint8)
pink = tensor([255, 0, 255], dtype=torch.uint8)
violet = tensor([226, 43, 138], dtype=torch.uint8)
white = tensor([255, 255, 255], dtype=torch.uint8)
def _step(state):
# make our life easier by creating a view with a single leading dim
state_flat = state.view(prod(state.shape))
batch_range = torch.arange(state_flat.size(0), device=state.device)
# move player position checking for collisions
direction = action_vec.to(state.device)
next_player_pos = state_flat['player_pos'] + direction[state_flat['action'][:, 0]].to(state.device)
next_player_grid = torch.zeros_like(state_flat['wall_tiles'], dtype=torch.bool, device=state.device)
next_player_grid[batch_range, next_player_pos[:, 0], next_player_pos[:, 1]] = True
collide_wall = torch.logical_and(next_player_grid, state_flat['wall_tiles'] == 1).any(-1).any(-1)
player_pos = torch.where(collide_wall[..., None], state_flat['player_pos'], next_player_pos)
player_pos_mask = torch.zeros_like(state_flat['wall_tiles'], dtype=torch.bool, device=state.device)
player_pos_mask[batch_range, player_pos[:, 0], player_pos[:, 1]] = True
player_pos = player_pos.reshape(state['player_pos'].shape)
player_pos_mask = player_pos_mask.reshape(state['wall_tiles'].shape)
# pickup any rewards
reward = state['reward_tiles'][player_pos_mask]
state['reward_tiles'][player_pos_mask] = 0.
# set done flag if hit done tile
done = state['done_tiles'][player_pos_mask]
next = {
'player_pos': player_pos,
'wall_tiles': state['wall_tiles'],
'reward_tiles': state['reward_tiles'],
'done_tiles': state['done_tiles'],
'reward': reward,
'done': done
}
return TensorDict({'next': next}, state.shape)
def _reset(self, state=None):
batch_size = state.shape if state is not None else self.batch_size
if state is None or state.is_empty():
state = self.gen_params(batch_size)
if '_reset' in state.keys():
reset_state = self.gen_params(batch_size).to(state.device)
state = state.clone()
for key in reset_state.keys():
state[key][state['_reset'].squeeze(-1)] = reset_state[key][state['_reset'].squeeze(-1)]
state['done'][state['_reset'].squeeze(-1)] = False
state['reward'][state['_reset'].squeeze(-1)] = 0.
return state
def gen_params(batch_size=None):
walls = tensor([
[1, 1, 1, 1, 1],
[1, 0, 0, 0, 1],
[1, 0, 0, 0, 1],
[1, 0, 0, 0, 1],
[1, 1, 1, 1, 1],
], dtype=torch.uint8)
rewards = tensor([
[0, 0, 0, 0, 0],
[0, 1, 1, -1, 0],
[0, 1, 0, 1, 0],
[0, -1, 1, 1, 0],
[0, 0, 0, 0, 0],
], dtype=torch.float32)
dones = tensor([
[0, 0, 0, 0, 0],
[0, 0, 0, 1, 0],
[0, 0, 0, 0, 0],
[0, 1, 0, 0, 0],
[0, 0, 0, 0, 0],
], dtype=torch.bool)
player_pos = tensor([2, 2], dtype=torch.int64)
observation = {
"player_pos": player_pos,
"wall_tiles": walls,
"reward_tiles": rewards,
"done_tiles": dones
}
td = TensorDict(observation, batch_size=[])
if batch_size:
td = td.expand(batch_size).contiguous()
return td
def _make_spec(self, td_params):
batch_size = td_params.shape
self.observation_spec = CompositeSpec(
wall_tiles=BoundedTensorSpec(
minimum=0,
maximum=1,
shape=torch.Size((*batch_size, 5, 5)),
dtype=torch.uint8,
),
reward_tiles=UnboundedContinuousTensorSpec(
shape=torch.Size((*batch_size, 5, 5)),
dtype=torch.float32,
),
done_tiles=BoundedTensorSpec(
minimum=0,
maximum=1,
shape=torch.Size((*batch_size, 5, 5)),
dtype=torch.bool,
),
player_pos=UnboundedDiscreteTensorSpec(
shape=torch.Size((*batch_size, 2,)),
dtype=torch.int64
),
shape=torch.Size((*batch_size,))
)
self.input_spec = self.observation_spec.clone()
self.action_spec = DiscreteTensorSpec(4, shape=torch.Size((*batch_size, 1)))
self.reward_spec = UnboundedContinuousTensorSpec(shape=torch.Size((*batch_size, 1)))
def _set_seed(self, seed: Optional[int]):
rng = torch.manual_seed(seed)
self.rng = rng
class Gridworld(EnvBase):
metadata = {
"render_modes": ["human", ""],
"render_fps": 30
}
batch_locked = False
def __init__(self, td_params=None, device="cpu", batch_size=None):
if td_params is None:
td_params = self.gen_params(batch_size)
super().__init__(device=device, batch_size=batch_size)
self._make_spec(td_params)
self.shape = batch_size
gen_params = staticmethod(gen_params)
_make_spec = _make_spec
_reset = _reset
_step = staticmethod(_step)
_set_seed = _set_seed
class RGBFullObsTransform(Transform):
def forward(self, tensordict):
return self._call(tensordict)
def _call(self, td):
td_flat = td.view(prod(td.batch_size))
batch_range = torch.arange(td_flat.size(0), device=td.device)
player_pos = td_flat['player_pos']
walls = td_flat['wall_tiles']
rewards = td_flat['reward_tiles']
grid = TensorDict({'image': torch.zeros(*walls.shape, 3, dtype=torch.uint8)}, batch_size=td_flat.batch_size)
x, y = player_pos[:, 0], player_pos[:, 1]
grid['image'][walls == 1] = white
grid['image'][rewards > 0] = green
grid['image'][rewards < 0] = red
grid['image'][batch_range, x, y, :] = yellow
grid['image'] = grid['image'].permute(0, 3, 1, 2)
td['observation'] = interpolate(grid['image'], size=[64, 64]).squeeze(0)
return td
@_apply_to_composite
def transform_observation_spec(self, observation_spec):
return BoundedTensorSpec(
minimum=0,
maximum=255,
shape=torch.Size((*self.parent.batch_size, 3, 64, 64)),
dtype=torch.uint8,
device=observation_spec.device
)
if __name__ == '__main__':
from matplotlib import pyplot as plt
import matplotlib.animation as animation
env = Gridworld(batch_size=torch.Size([64]), device='cuda')
check_env_specs(env)
env = TransformedEnv(
env,
RGBFullObsTransform(in_keys=['player_pos', 'wall_tiles'], out_keys=['observation'])
)
check_env_specs(env)
data = env.rollout(max_steps=100, policy=env.rand_action, break_when_any_done=False)
data = data.cpu()
"""
The data dict layout is transitions
{(S, A), next: {R_next, S_next, A_next}}
[
{ state_t0, reward_t0, done_t0, action_t0 next: { state_t2, reward_t2:1.0, done_t2:False } },
{ state_t1, reward_t1, done_t1, action_t1 next: { state_t3, reward_t2:-1.0, done_t3:True } }
{ state_t0, reward_t0, done_t0, action_t0 next: { state_t3, reward_t2:1.0, done_t3:False } }
]
But which R to use, R or next: R?
recall: Q(S, A) = R + Q(S_next, A_next)
Observe that reward_t0 is always zero, reward is a consequence for taking an action in a state, therefore...
reward = data['next']['reward'][timestep]
Which done to use?
Recall that the value of a state is the expectation of future reward.
Thus the terminal state has no value, therefore...
Q(S, A) = R_next + Q(S_next, A_next) * done_next
done = data['next']['done'][timestep]
"""
fig, ax = plt.subplots(1)
img_plt = ax.imshow(make_grid(data[:, 0]['observation']).permute(1, 2, 0))
def animate(i):
global text_plt
x = make_grid(data[:, i]['observation']).permute(1, 2, 0)
img_plt.set_data(x)
return
myAnimation = animation.FuncAnimation(fig, animate, frames=20, interval=1, blit=False, repeat=False)
FFwriter = animation.FFMpegWriter(fps=1)
myAnimation.save('animation.mp4', writer=FFwriter)
plt.show()