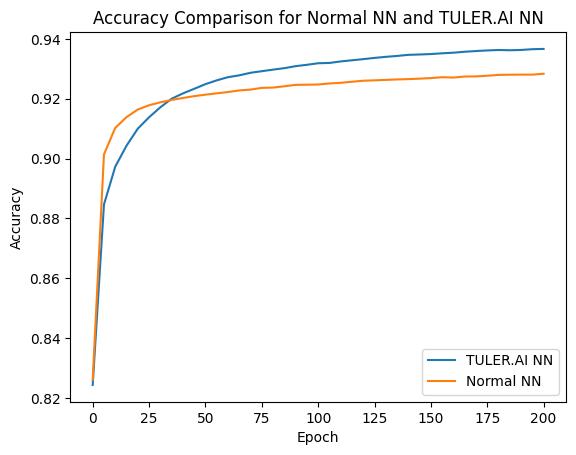
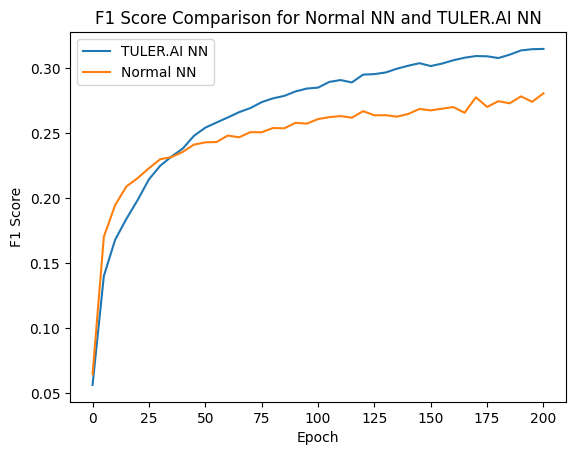
Hello, I developed a new way of working with Neural Networks, a new feedforward, and architecture.
Also a Brain-Inspired Neural Activation Module.
I want to add those methods to torch modules, So please could you help me in the process of contributing or get in touch with PyTorch Staff
the repository: GitHub - salah55s/TULER.ai
Using parameter based activation may reduce the information bottleneck in neural networks.
I think one way of going further is to double the number of weights in a neural network by 2 Siding ReLU via its forward weight connections (not backward weight connections.):
this is a demo showing what is going on with each neuron, each neuron is forced to have its own activation function as shown, it always starts with very random results, but it shortly converges because of its fine-grained control " Actually there are other equations instead of
torch.where(output >= self.thresholds, self.parm5 + self.parm2 * (output - self.parm4), self.parm3 * output)
but as much as you go fast without negative values (like ReLU) as you will face lots of overfitting problems
the first aim of the work was “How to overcome overfitting” and it ended up with “How to boost the ML itself”
And as you mentioned, such a way will be beneficial in reducing the information bottleneck in neural networks. And as you see, I was focusing on the way of the Human Brain, but it’s an amazing idea!
Your insights are greatly appreciated!
Thanks for your work and insights. I still have some information bottleneck problems with one type of neural network I experiment with, where I have to make the network wider than I would like, to compensate. I will think about your solution and try to apply it.
About the information bottleneck: My work was focusing on mimicking the way of the human brain to avoid overfitting, as the brain is over-parameterized and still does not have a problem of overfitting
We may think about memorizing as an overfitting mechanism, but the human brain still has the ability to analyze well!
So, I think the need for a wider network is to be “smart enough” for the desired task, is because of the mimicking of the HUMAN BRAIN, as you make each neuron has powerful tools( individual prams and others) but in a very narrow scale( as each duty for each neuron is forced to do only sth with its own threshold and activation, not to have a range of outputs based on only inputs-weights. Therefore, in general, using TULERNN will make your model smarter, you may need a wider or more parameterized model and this is not a problem for now, as even with this method, you will have better performance.
Also, The missing piece is, sth to replace the dropout “Actually it is not missing, I’m developing it to be like the inhibition mechanism in neurons, it will really different story to tell, and it is the exact point that touches the overfitting and information bottleneck problems” with.