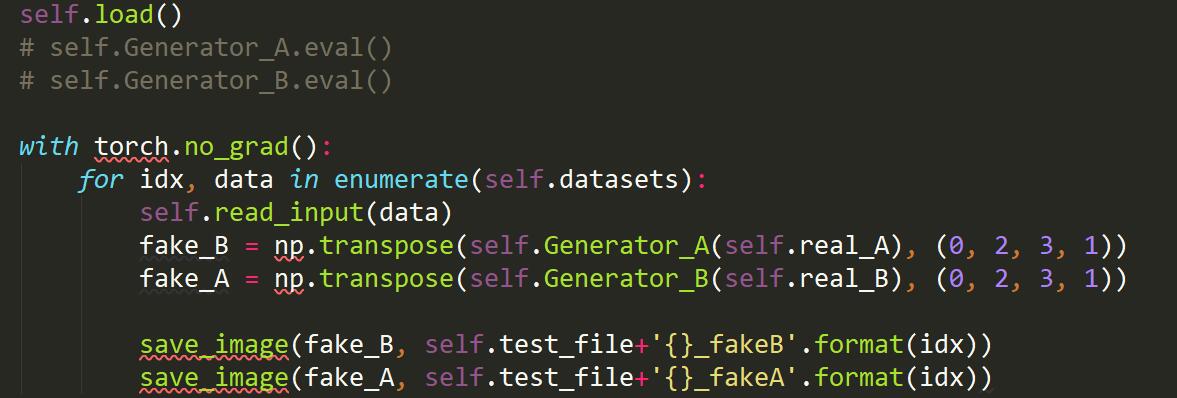
The problem is, if I follow the advise in document, using eval() when testing, my outputs will be quite strange. But if I cancel them, the results turn to be much better.
I’ve learned that this function influences bn-layers and dropout-layers, but I don’t know why there was such big difference between outputs generated in training and testing. When I used my tensorflow code, the outputs were similar. Did I miss something?
Thank you for your reply.
My level didn’t allow me to post more than one image yesterday. There are some images during my training yesterday.(early stopping)
with eval()
without eval()
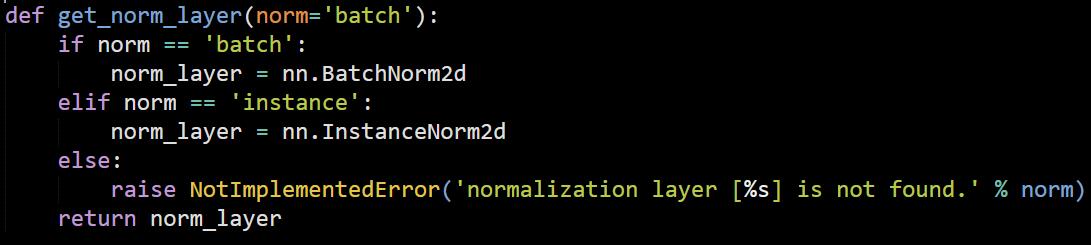
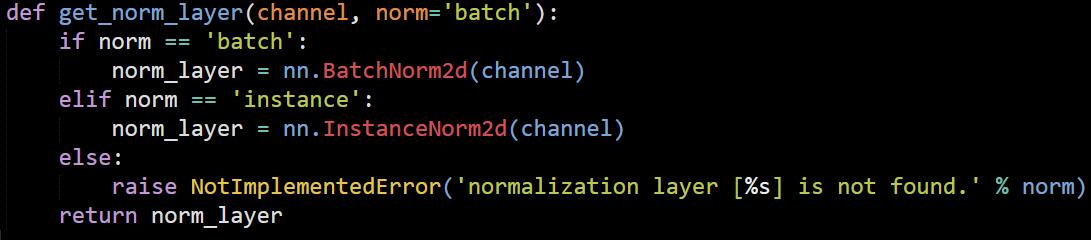
I’ve solved this problem today. It seemed that I’d used the same batch-norm layer for several times by mistake…hmmm I’m not sure in fact. Is there any difference between the codes?