I just started learning NLP and RNN. I read O’Reilly’s Deep Learning: natrual language processing, and here’s the Figure showing batch-training in RNN:
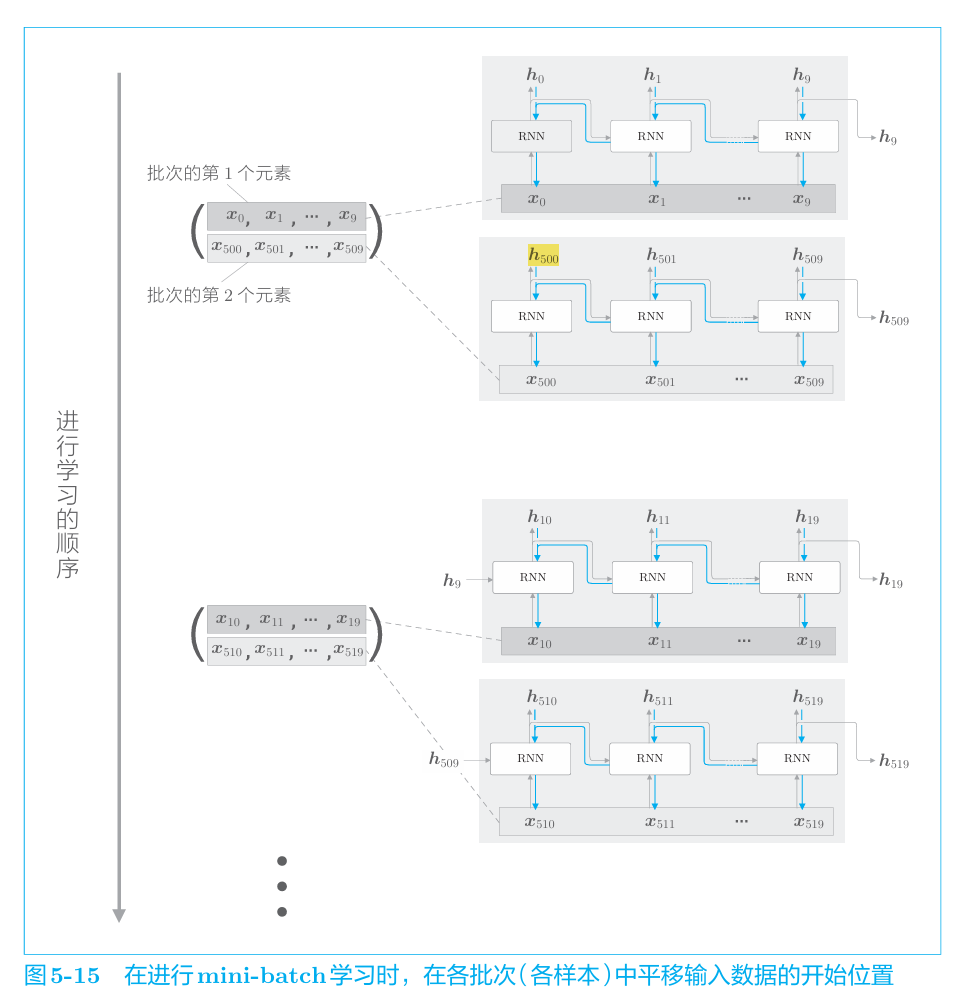
(please ignore its Chinese Characters which are not important)
In the above figure, the author uses Truncated BPTT as an example to show how to traing from a 1000-word time series, truncated at every 10 words, with batch size=2.
As the figure shows, the first sequence in first batch from X0, and the second sequence in first batch start from X500, which shift from X0 by 500. So does the other batch.
Then here comes my question: does this mean that all sequences in the first batch has no hidden state to inherit? For example, X500 does not have h499. What is more, does that mean that forward propagating is truncated at X500 (which indicates that the longest memory in this situation could only support 500 words)?