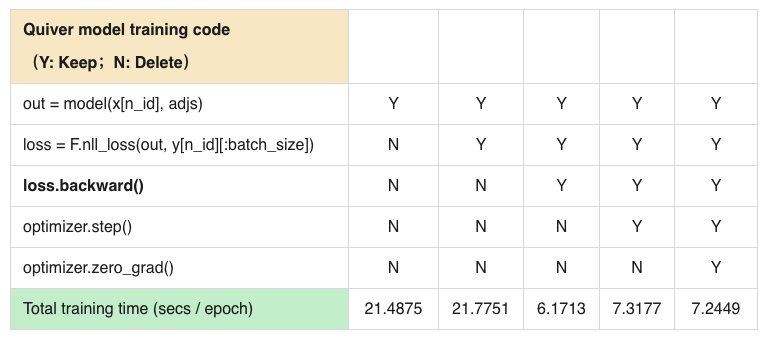
Ok, here I post a code example. Maybe you need to install torch-geometric and torch-quiver. Then the Reddit dataset should be downloaded automatically.
import os.path as osp
import torch
import torch.nn.functional as F
from tqdm import tqdm
from torch_geometric.datasets import Reddit
from torch_geometric.loader import NeighborSampler
from torch_geometric.nn import SAGEConv
import quiver
path = osp.join(osp.dirname(osp.realpath(__file__)), '..', 'data', 'Reddit')
dataset = Reddit(path)
data = dataset[0]
train_idx = data.train_mask.nonzero(as_tuple=False).view(-1)
train_loader = torch.utils.data.DataLoader(train_idx,
batch_size=128,
shuffle=True,
drop_last=False) # Quiver
csr_topo = quiver.CSRTopo(data.edge_index) # Quiver
quiver_sampler = quiver.pyg.GraphSageSampler(csr_topo, sizes=[25, 10], device=0, mode='UVA') # Quiver
class SAGE(torch.nn.Module):
def __init__(self, in_channels, hidden_channels, out_channels):
super(SAGE, self).__init__()
self.num_layers = 2
self.convs = torch.nn.ModuleList()
self.convs.append(SAGEConv(in_channels, hidden_channels))
self.convs.append(SAGEConv(hidden_channels, out_channels))
def forward(self, x, adjs):
for i, (edge_index, _, size) in enumerate(adjs):
x_target = x[:size[1]] # Target nodes are always placed first.
x = self.convs[i]((x, x_target), edge_index)
if i != self.num_layers - 1:
x = F.relu(x)
x = F.dropout(x, p=0.5, training=self.training)
return x.log_softmax(dim=-1)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = SAGE(dataset.num_features, 256, dataset.num_classes)
model = model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
x = data.x.to(device) # Original PyG Code
y = data.y.squeeze().to(device)
def train(epoch, mode=0):
model.train()
if mode == 0:
total_time = 0
for seeds in train_loader:
torch.cuda.synchronize()
start = time.time()
n_id, batch_size, adjs = quiver_sampler.sample(seeds) # Quiver
adjs = [adj.to(device) for adj in adjs]
out = model(x[n_id], adjs)
loss = F.nll_loss(out, y[n_id[:batch_size]])
loss.backward()
optimizer.step()
optimizer.zero_grad()
torch.cuda.synchronize()
total_time += time.time() - start
print("Epoch %s elpased total time: %s" % (epoch, total_time))
return total_time
elif mode == 1:
sample_time = 0
for seeds in train_loader:
torch.cuda.synchronize()
start = time.time()
n_id, batch_size, adjs = quiver_sampler.sample(seeds) # Quiver
adjs = [adj.to(device) for adj in adjs]
torch.cuda.synchronize()
sample_time += time.time() - start
print("Epoch %s elapsed sample time: %s" % (epoch, sample_time))
return sample_time
total_time = []
for epoch in range(0, 20):
e_time = train(epoch, mode=0)
total_time.append(e_time)
print("Average time: %s, num_workers: %s, batch_size: %s, hidden_size: %s" \
% (sum(total_time[2:]) / 18, 0,
128, 256))