Namespace(batch_size=32, cuda=True, d_inner_hid=2048, d_k=64, d_model=512, d_v=64, d_word_vec=512, data=‘data/multi30k.atok.low.pt’, dropout=0.1, embs_share_weight=False, epoch=10, label_smoothing=True, log=None, max_token_seq_len=102, n_head=8, n_layers=6, n_warmup_steps=4000, no_cuda=False, proj_share_weight=True, save_mode=‘best’, save_model=‘data/trained’, src_vocab_size=28699, tgt_vocab_size=52799)
cuda device count: 2
[ Epoch 0 ]
- (Training) : 79%|▊| 7034/8883 [56:34<15:09, 2.03it/s]
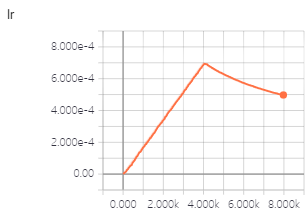
learning rate update code:
def _get_lr_scale(self):
return np.min([np.power(self.n_current_steps, -0.5), np.power(self.n_warmup_steps, -1.5) * self.n_current_steps])
def _update_learning_rate(self):
''' Learning rate scheduling per step '''
self.n_current_steps += 1
lr = self.init_lr * self._get_lr_scale()
#
for param_group in self._optimizer.param_groups:
param_group['lr'] = lr
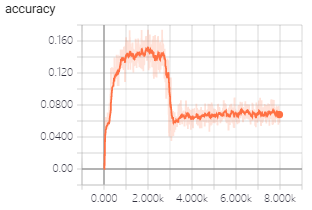
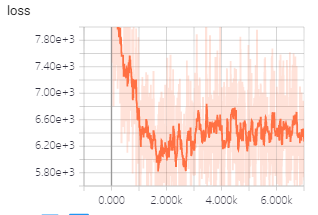
I use transformer model to train machine traslation, but in first epoch i meet the above strange phenomenon/problem.
- Why does loss increase?
2.Why does accuracy decrease?