Code first ;
import torch
x = torch.ones((2,10), requires_grad=True)
z = torch.ones((1,10), requires_grad=True)
y = (4 * x * x + 10 * z).mean()
y.backward()
print('x grad :', x.grad)
print('z grad:', z.grad)
print('y grad:', y.grad)
it’s output
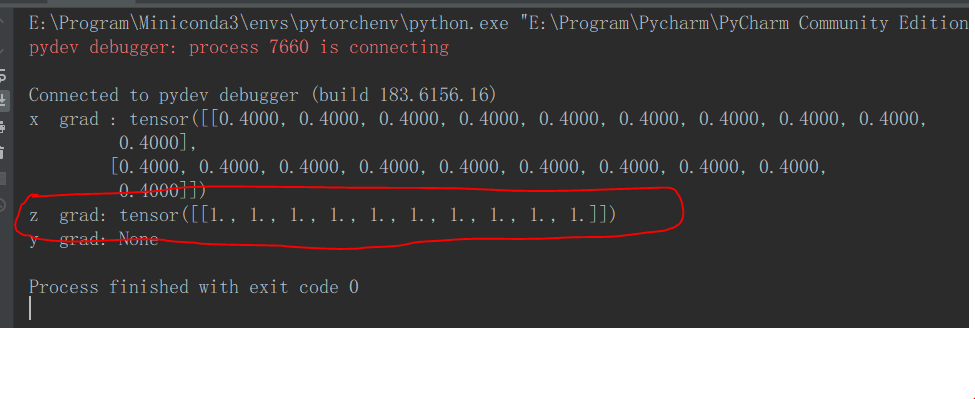
As we can see, if we write code like above without tensor.cuda() , tensor x,z has a grad here;
But if we change tensor x,y to cuda like below with tensor.cuda() ;
import torch
x = torch.ones((2,10), requires_grad=True).cuda()
z = torch.ones((1,10), requires_grad=True).cuda()
y = (4 * x * x + 10 * z).mean()
y.backward()
print('x grad :', x.grad)
print('z grad:', z.grad)
print('y grad:', y.grad)
If we write like this , the grad will be None , what a strange thing , what happend here?
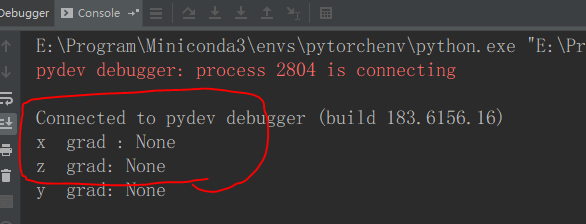
I’m not new to pytorch , I have learned and used pytorch for a long time , but it’s the first time that I meet such a thing like this .
Could anyone helps me about it ? Thanks for your reply