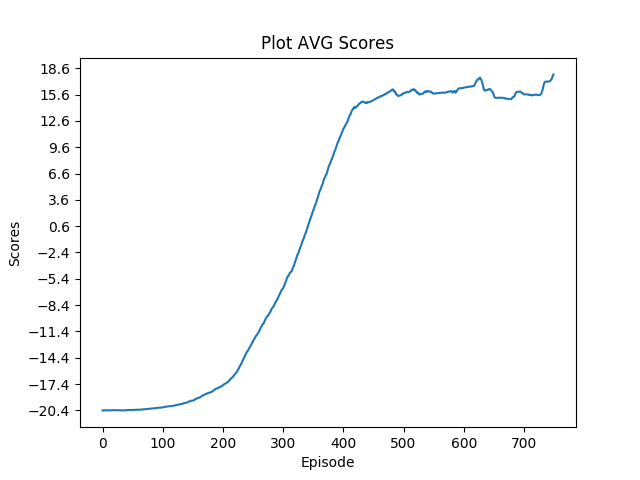
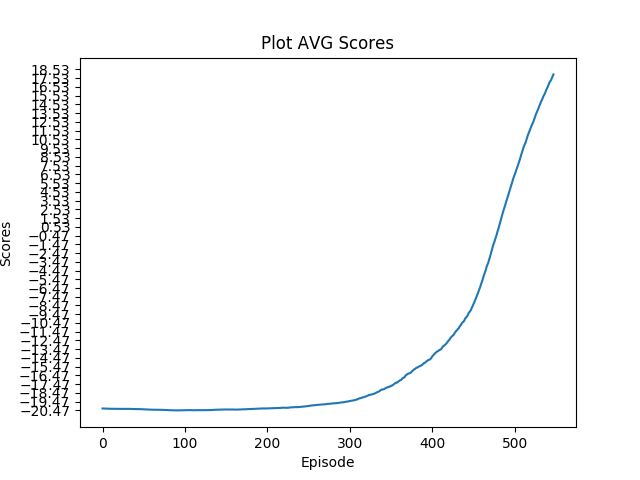
Hi,
I’m developing an A3C algorithm relying on torch.multiprocessing on PongNoFrameSkip-v4. The algorithm works well on PyTorch versions <=1.13.1, however when moving the code in PyTorch versions >=2.0.0. the algorithm gets stuck and does not improve anymore, even after a long time.
The model used is:
class ActorCritic(torch.nn.Module):
def __init__(self,input_shape, layer1, kernel_size1, stride1, layer2, kernel_size2, stride2, fc1_dim, lstm_dim, out_actor_dim, out_critic_dim):
super(ActorCritic, self).__init__()
self.conv1 = torch.nn.Conv2d(in_channels=input_shape, out_channels=layer1, kernel_size=kernel_size1, stride=stride1)
self.conv2 = torch.nn.Conv2d(in_channels=layer1, out_channels=layer2, kernel_size=kernel_size2, stride=stride2)
self.relu = torch.nn.ReLU()
self.fc1 = torch.nn.Linear(in_features=32*9*9, out_features=fc1_dim)
self.out_actor = torch.nn.Linear(in_features=lstm_dim, out_features=out_actor_dim)
self.out_critic = torch.nn.Linear(in_features=lstm_dim, out_features=out_critic_dim)
#lstm cell
self.lstm_cell = torch.nn.LSTMCell(fc1_dim, lstm_dim)
for layer in self.modules():
if isinstance(layer, torch.nn.Conv2d):
torch.nn.init.kaiming_normal_(layer.weight, nonlinearity="relu")
layer.bias.data.zero_()
for name, param in self.lstm_cell.named_parameters():
if 'bias' in name:
param.data.zero_()
elif 'weight' in name:
torch.nn.init.xavier_uniform_(param)
torch.nn.init.xavier_uniform_(self.fc1.weight)
self.fc1.bias.data.zero_()
torch.nn.init.xavier_uniform_(self.out_critic.weight)
self.out_critic.bias.data.zero_()
torch.nn.init.xavier_uniform_(self.out_actor.weight)
self.out_actor.bias.data.zero_()
def forward(self,x):
x, (hx, cx) = x
out_backbone = self.conv1(x)
out_backbone = self.relu(out_backbone)
out_backbone = self.conv2(out_backbone)
out_backbone = self.relu(out_backbone)
out = out_backbone.view(out_backbone.size(0), -1)
out = self.fc1(out)
out = self.relu(out)
#lstm cell
hx, cx = self.lstm_cell(out, (hx, cx))
out = hx
#actor
actor = self.out_actor(out)
#critic
critic = self.out_critic(out)
return actor,critic,(hx, cx)
The training function is as follow:
def train(p_i, shared_model, p, optimizer, lock, counter, lys, avg_ep, scores, scores_avg, flag_exit):
params = p.copy()
layers_ = lys.copy()
seed = params['seed']
torch.manual_seed(seed + p_i)
np.random.seed(seed + p_i)
env = gym.make(params['env_name'])
env.seed(seed + p_i)
env.observation_space.np_random.seed(seed + p_i)
env.action_space.np_random.seed(seed + p_i)
actions_name = env.unwrapped.get_action_meanings()
print(' ----- TRAIN PHASE -----')
#create instance of the model
model = ActorCritic(input_shape=layers_['n_frames'], layer1=layers_['hidden_dim1'], kernel_size1=layers_['kernel_size1'], stride1=layers_['stride1'], layer2=layers_['hidden_dim2'],
kernel_size2=layers_['kernel_size2'], stride2=layers_['stride2'], fc1_dim=layers_['fc1'],
lstm_dim=layers_['lstm_dim'], out_actor_dim=layers_['out_actor_dim'], out_critic_dim=layers_['out_critic_dim'])
if optimizer is None:
optimizer = torch.optim.Adam(shared_model.parameters(), lr=params['lr'])
model.train()
#reset env
queue = deque(maxlen=4)
in_state_i = env.reset()
#initialize a queue for each env, preprocess each frame and obtain a vecotr of 84,84,4
frame_queue = initialize_queue(queue, layers_['n_frames'], in_state_i, env, actions_name)
#stack the frames together
input_frames = stack_frames(frame_queue)
current_state = input_frames
episode_length = 0
tot_rew = 0
#initialization lstm hidden state
hx = torch.zeros(1, layers_['lstm_dim'])
cx = torch.zeros(1, layers_['lstm_dim'])
while True:
#stop workers when the avg > mean reward
if flag_exit.value == 1:
print(f"Terminating process n. {p_i}...")
break
#Sync with the shared model
model.load_state_dict(shared_model.state_dict())
#rollout_step
hx, cx, steps_array, episode_length, frame_queue, current_state, tot_rew, counter, flag_finish, scores_avg = rollout(p_i, counter, params, model, hx, cx, frame_queue, env, current_state,
episode_length, actions_name, layers_, tot_rew, scores, lock, avg_ep, scores_avg)
if flag_finish == True:
print('Save Model...')
torch.save(shared_model,'./saved_model/shared_model.pt')
plot_avg_scores(scores_avg, 'Plot AVG Scores')
with flag_exit.get_lock():
flag_exit.value = 1
break
#compute expected returns
probs, log_probs, action_log_probs, advantages, returns, values = compute_returns(steps_array, params['gamma'], model)
# compute losses and update parameters
a3c_loss, value_loss, policy_loss, entropy_loss = update_parameters(probs, log_probs, action_log_probs, advantages, returns, values, params['value_coeff'], params['entropy_coef'])
optimizer.zero_grad()
a3c_loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), params['max_grad_norm'])
ensure_shared_grads(model, shared_model)
optimizer.step()
if counter.value % 100 == 0:
print(f'Process: {p_i} \nUpdate: {counter.value} \nPolicy_Loss: {policy_loss.item()} \nValue_Loss: {value_loss.item()} \nEntropy_Loss: {entropy_loss.item()} \nA3C loss: {a3c_loss.item()} \n')
print('------------------------------------------------------')
with counter.get_lock():
counter.value += 1
where the function considered are:
def rollout(p_i, counter, params, model, hx, cx, frame_queue, env, current_state, episode_length, actions_name, layers_, tot_rew, scores, lock, avg_ep, scores_avg):
#empty lists
states = []
actions = []
rewards = []
masks = []
hx_s = []
cx_s = []
steps_array = []
flag_finish = False
for _ in range(params['rollout_size']):
episode_length +=1
current_state = current_state.unsqueeze(0).permute(0,3,1,2)
with torch.no_grad():
#compute logits, values and hidden and cell states from the current state
logits, _ , (hx_, cx_) = model((current_state,(hx, cx)))
#get action
action, _, _ = compute_log_prob_actions(logits)
#permorm step in the env
next_frame, reward, done, _ = skip_frames(action,env,skip_frame=4)
#reward = max(min(reward, 1), -1)
states.append(current_state)
actions.append(action)
rewards.append(np.sign(reward))
masks.append(done)
hx_s.append(hx)
cx_s.append(cx)
tot_rew +=reward
frame_queue.append(frame_preprocessing(next_frame))
next_state = stack_frames(frame_queue)
current_state = next_state
hx, cx = hx_, cx_
if episode_length > params['max_ep_length']:
break
if done:
#reset env
in_state_i = env.reset()
frame_queue = initialize_queue(frame_queue, layers_['n_frames'], in_state_i, env, actions_name)
#stack the frames together
input_frames = stack_frames(frame_queue)
current_state = input_frames
episode_length = 0
print(
"Process: ", p_i,
"Update:", counter.value,
"| Ep_r: %.0f" % tot_rew,
)
print('------------------------------------------------------')
flag_finish, scores_avg = print_avg(scores, p_i, tot_rew, lock, avg_ep, params, flag_finish, scores_avg)
print('\n')
if flag_finish == True:
break
tot_rew = 0
hx = torch.zeros(1, layers_['lstm_dim'])
cx = torch.zeros(1, layers_['lstm_dim'])
#bootstrapping
with torch.no_grad():
_, f_value , _ = model((current_state.unsqueeze(0).permute(0,3,1,2),(hx_, cx_)))
steps_array.append((states, actions, rewards, masks, hx_s, cx_s, f_value))
return hx, cx, steps_array, episode_length, frame_queue, current_state, tot_rew, counter, flag_finish, scores_avg
Then:
def compute_returns(steps_array, gamma, model):
states, actions, rewards, masks, hx_s, cx_s, f_value = steps_array[0]
R = f_value
returns = torch.zeros(len(rewards),1)
for j in reversed(range(len(rewards))):
R = rewards[j] + R * gamma * (1-masks[j])
returns[j] = R
#batch of states
s = torch.concat(states, dim=0)
a = torch.tensor(actions).unsqueeze(1)
hxs = torch.cat(hx_s)
cxs = torch.cat(cx_s)
#compute probs and logproba
logits, values, _ = model((s,(hxs, cxs)))
probs = torch.nn.functional.softmax(logits, dim=-1)
log_probs = torch.nn.functional.log_softmax(logits, dim=-1)
#gather logprobs with respect the chosen actions
action_log_probs = log_probs.gather(1, a)
#advantages
advantages = returns - values
return probs, log_probs, action_log_probs, advantages, returns, values
and finally to update the parameters:
def update_parameters(probs, log_probs, action_log_probs, advantages, returns, values, value_coeff, entropy_coef):
#policy loss
policy_loss = -(action_log_probs * advantages.detach()).mean()
#value loss
value_loss = torch.nn.functional.mse_loss(values, returns)
#entropy loss
entropy_loss = (probs * log_probs).sum(dim=1).mean()
a3c_loss = policy_loss + value_coeff * value_loss + entropy_coef * entropy_loss
return a3c_loss, value_loss, policy_loss, entropy_loss
To synchronize the gradients I used, as in other implementations:
def ensure_shared_grads(local_model, shared_model):
for param, shared_param in zip(local_model.parameters(),shared_model.parameters()):
if shared_param.grad is not None:
return
shared_param.grad = param.grad
The main is similar to the one found in the PyTorch docs for multiprocessin:
shared_ac = ActorCritic(input_shape=layers_['n_frames'], layer1=layers_['hidden_dim1'], kernel_size1=layers_['kernel_size1'], stride1=layers_['stride1'], layer2=layers_['hidden_dim2'],
kernel_size2=layers_['kernel_size2'], stride2=layers_['stride2'], fc1_dim=layers_['fc1'],
lstm_dim=layers_['lstm_dim'], out_actor_dim=layers_['out_actor_dim'], out_critic_dim=layers_['out_critic_dim'])
shared_ac.share_memory()
#shared optimizer
if params['optimizer'] == 'adam':
print('Use Adam Shared optimizer ...')
optimizer = SharedAdam(shared_ac.parameters(), lr=params['lr'])
optimizer.share_memory()
elif params['optimizer'] == 'rmsprop':
print('Use RMSprop Shared optimizer ...')
optimizer = SharedRMSprop(shared_ac.parameters(), lr=params['lr'])
optimizer.share_memory()
else:
optimizer = None
counter_updates = mp.Value('i', 0)
counter_test = mp.Value('i', 0)
shared_ep, shared_r = mp.Value('i', 0), mp.Value('d', 0.)
lock = mp.Lock()
avg_ep = mp.Value('i', 0)
scores = mp.Manager().list()
scores_avg = mp.Manager().list()
flag_exit = mp.Value('i', 0)
n_processes = params['n_process']
print('n_processes: ', n_processes)
print('rollout size: ', params['rollout_size'])
processes = []
for p_i in range(0, n_processes):
p = mp.Process(target=train, args=(p_i, shared_ac, params, optimizer,lock, counter_updates, layers_, avg_ep, scores, scores_avg, flag_exit))
p.start()
processes.append(p)
time.sleep(5)
for p in processes:
p.join()
for p in processes:
p.terminate()
Based on the code, do you have any idea of where a problem could occur making the algorithm not converge in PyTorch 2.0.0? I don’t have any errors in the terminal when launching and executing the code.
Thank you in advance.
Gianluca.