I use a server to run Stable Video diffusion models on RTX A6000, then I find that with different batch sizes, the generated videos are slightly different (all the random seeds are fixed). Then I run the same sampling on my RTX 3090, the results are the same for different batch sizes, and the results are different with the results from A6000 (random seeds are also fixed).
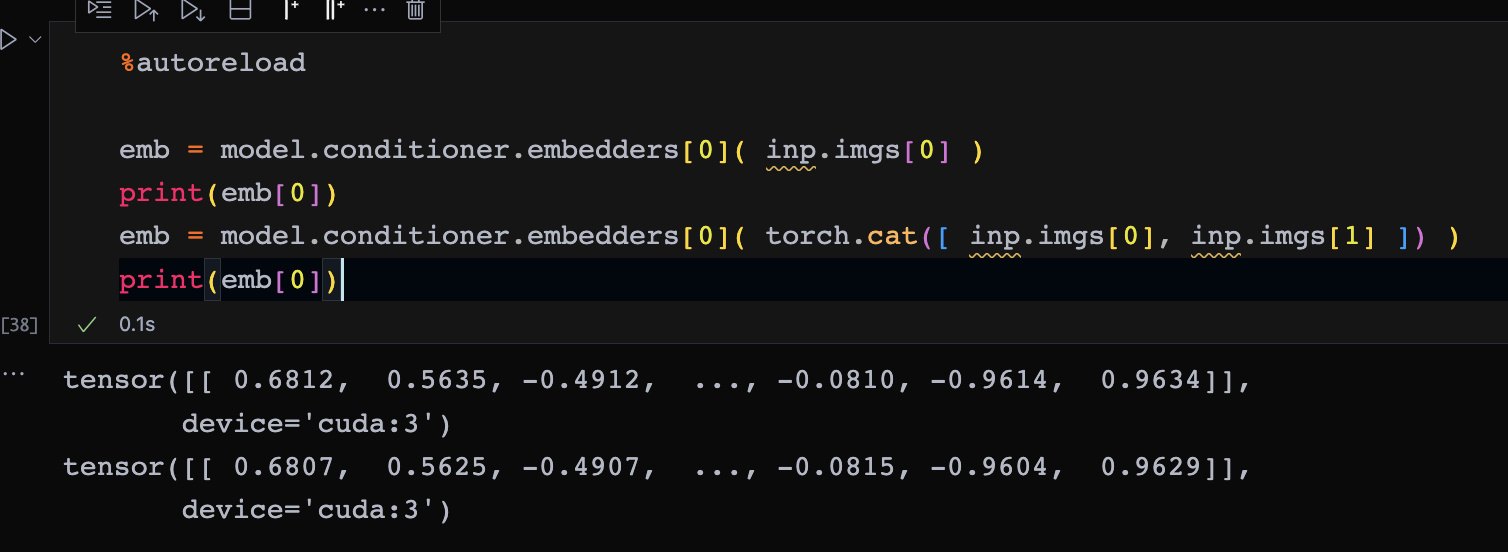
I perform a simple experiment on A6000, I input an image to a CLIP image encoder, with batch size 1 and 2. The two results are slightly different as shown in the figure below. This experiment gives exactly the same results on my 3090 card, what happens to A6000? The datatypes are both torch.float32, and I also checked that there are no BatchNorm or other random processes in CLIP image encoder.
And I also try other models, with different batch sizes, the outputs always have a difference. And each element may have different errors (0.0005 or 0.001) or no errors. It’s really weird!
Results are well-defined only up to numerical accuracy. Even when things are deterministic on a system, if you run it on a different one, you might get different results.
Ultimately, this is more or less a result of elementary floating-point operations not being associative, so subtle changes in how a computation is organized suddenly matter.
Here is a very example that I can run my computer (with a 3090 card and recent PyTorch from git) to relatively reliably get such an effect:
In [1]: import torch
In [2]: a = torch.randn(4096, 4096, device="cuda")
In [3]: a[:100, :100].sum().item()
Out[3]: 51.92887878417969
In [4]: a[:100, :100].clone().sum().item()
Out[4]: 51.928890228271484
If I were to run lines 3 and 4 repeatedly, I would get the exact same results for them, but changing the layout of the array from a contiguous one (with the clone) to one that has gaps (without the clone) changes the value by a tiny bit, as the computation is organized differently.
Of course, here the difference is 1e-5ish but you might imagine that when you have a complex computation, in particular when involving things like normalization (which tends to amplify errors when the inputs are small), this easily gets to 1e-4 or 1e-3ish.
Interestingly, integer computations don’t suffer from this as much, so a fully quantized computation might have better reproducibility.
Best regards
Thomas
P.S.: Of course, the real answer is to not bother with the A6000 and send it to me instead.
Hi, Thomas, thanks for your reply! I could appreciate that the computation may not be consistent when the input or computation process is slightly different. But I am still unsure why the same code could run into different results on different machines. So I test the following code on 3090:
This should not be like this. After seeding everything, we should get exactly the same results across different machines. I remembered that when I copied some code from Google colab notebook, I could reproduce the results with stable diffusion, whose results should be fully dependent on the initial random noise.
To confirm this, I found another server running with 3090 and got result:
I further test the same code on three machines with numpy and torch(device=‘cpu’), all three machines output exactly the same results. So there must be some problem on the card A6000.
@Tonis one thing you should keep in mind is that we don’t guarantee the RNG to be consistent across GPU models.
So, for the same seed, you get different random numbers across A6000 versus 3090.
One test you can do is to change the code to generate randn on CPU, and then move it over to GPU, so that you use the same numbers across all devices.