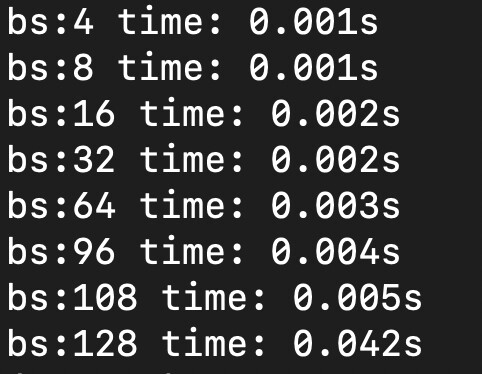
When I increase batch size, the forward time increases unlinearly at some point.
For example, the forward time for bs size 32, 64, 96 is 0.002, 0.003, 0.005s. but the forward time increase to 0.042s when I set batch size to 128.
I don’t understand why this happened. Could someone help me?
result screenshot
reimplement code:
import torch
from contextlib import contextmanager
from torch import nn
@contextmanager
def measure_time(label):
start = torch.cuda.Event(enable_timing=True)
end = torch.cuda.Event(enable_timing=True)
start.record()
yield
end.record()
torch.cuda.synchronize()
elapsed_time = start.elapsed_time(end) / 1000
print(f'{label} time: {elapsed_time:.3f}s')
test_bs = [2, 4, 8, 16, 32, 64, 96, 108, 128]
model = nn.Conv2d(384, 128, 3, 1, 1)
model.to('cuda')
for bs in test_bs:
x = torch.randn(bs, 384, 32, 32).to('cuda')
with measure_time(f'bs:{bs}'):
y = model(x)