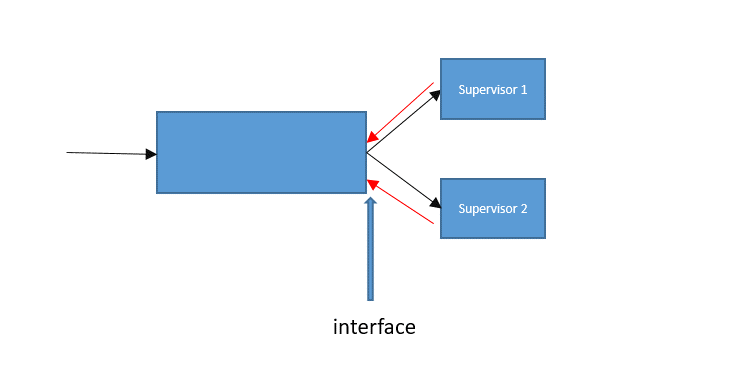
Hi, I am rather new to pytorch and working on a project. It comes to a point when I need to manipulate the gradients of the network. My question is:
I have a network with two supervisons. Usually, I use
loss1 = alpha*loss1
loss1.backward()
loss2 = (1-alpha)*loss2
loss2.backward()
However, if I understand this correctly, this seems to do the backpropagation twice on the network (the part before the interface). Is there any way to do something like:
#pseudocode
alpha*loss1.backward() till interface, save as error gradients1
(1-alpha)*loss2.backward() till interface, save as error gradients2
gradient = error gradients1 + error gradients2
resume the backprop on the network
Hello,
Is there any difference between these two methods you mentioned above?
In the first way, I am not really sure about the view of backpropagation twice, it calculates the gradients from supervisor1 and supervisro2 separately and performs accumulations on the shared part (before interface).
In the second way, it also seems to calculate separately and perform accumulations. What is the difference?
Thank you for the reply!
Do you meant that the backward on the shared part has been automatically taken care of by Pytorch? Maybe I should modify my question a little bit:
loss1 = alpha*loss1
loss1.backward()
loss2 = (1-alpha)*loss2
loss2.backward()
I am pretty sure this time the shared part gets two backwards (need retrain_graph=True). Do you think there is way to somehow accumulate the gradients before the shared part and resume the backprop with the combined gradients?
Yes, the accumulation is default operation (without optimizer.zero_grad).
And using the combination version and separate version are both right, they get the same result.
loss = loss1 + loss2
loss.backward()
# or
loss1.backward(retain_graph=True)
loss2.backward()
Therefore, you don’t need to accumulate the gradients of shared part and perform backprop manually.
Thank you for the explanation. Good to understand a little more about the autograd. Yes, the results are the same, at least theoretically. However, when you call two backward(), the two backpropagations will comsume more time than the one with the gradients combined before the shared part (I think calculating the gradients twice on the shared part should take double time).
I am trying to implement this (combining the gradients before the shared part) to save time. Do you think there is way to do this?