When I trained my program by 4 GPUs, like this:
CUDA_VISIBLE_DEVICES=0,1,2,3 python3 -m torch.distributed.launch --nproc_per_node=4 train.py
there would be an error:
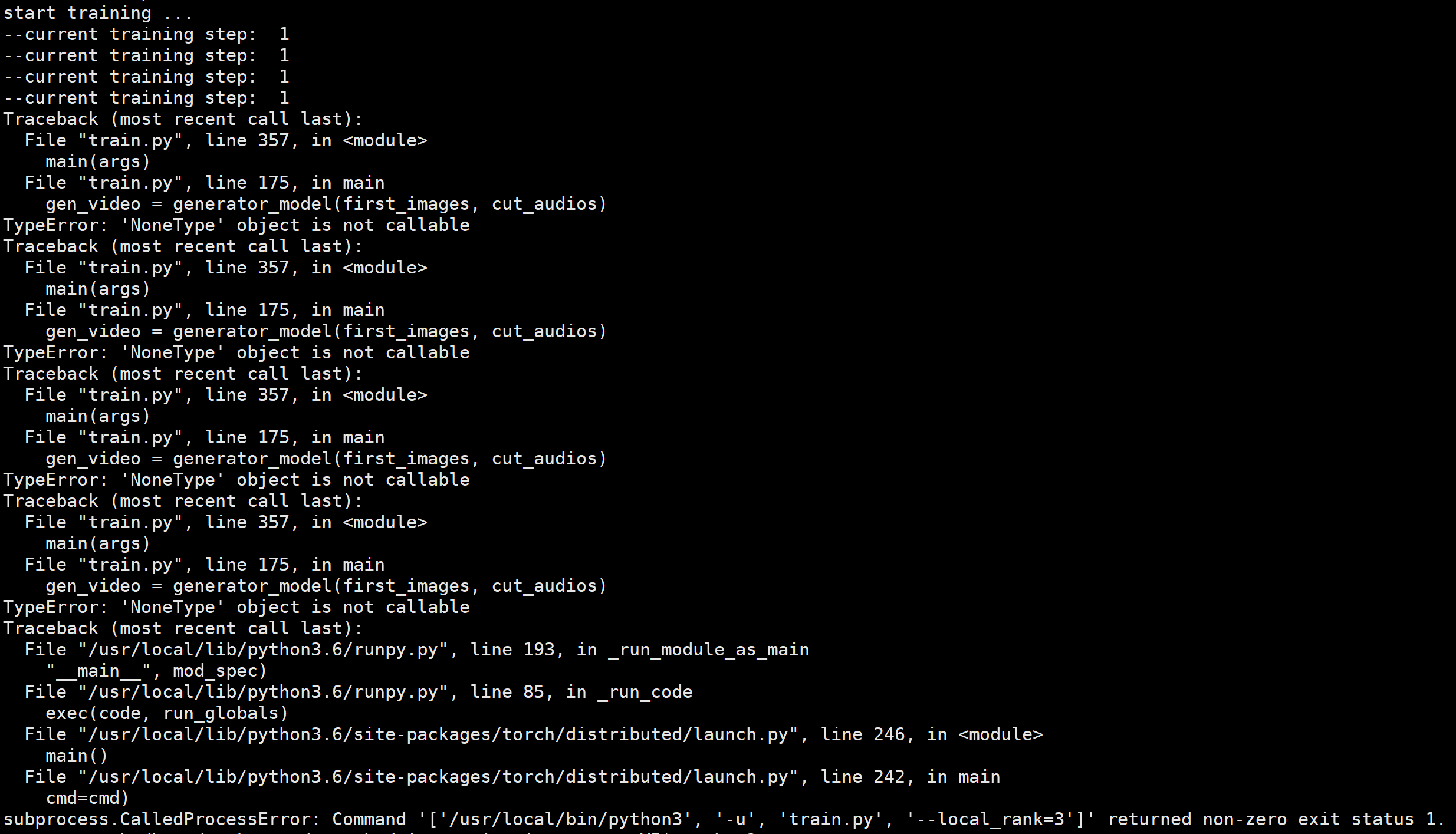
When using nn.DataParallel (), the program can be run. How can I locate this problem?
The snippet of my program is:
dist.init_process_group(backend=‘nccl’, init_method=“env://”)
generator_model = VideoGenerator().cuda(args.local_rank)
discriminator_1 = Discriminator_1().cuda(args.local_rank)
discriminator_2 = Discriminator_2().cuda(args.local_rank)
discriminator _3 = Discriminator_3().cuda(args.local_rank)
generator_model = torch.nn.parallel.DistributedDataParallel(generator_model,device_ids=[args.local_rank])
discriminator_1 = torch.nn.parallel.DistributedDataParallel(discriminator_1,device_ids=[args.local_rank])
discriminator_2 = torch.nn.parallel.DistributedDataParallel(discriminator_2,device_ids=[args.local_rank])
discriminator_3 = torch.nn.parallel.DistributedDataParallel(discriminator_3,device_ids=[args.local_rank])
generator_model.train()
train_sampler = …
train_loader = …
for i, batches in enumerate(train_loader):
first_images, cut_audios = batches
first_images = first_images.float().cuda(args.local_rank)
cut_audios = cut_audios.float().cuda(args.local_rank)
gen_video = generator_model(first_images, cut_audios) #(line 175)
…