Understood. In my opinion, with smaller lr, you don’t risk “overshoot” during gradient descent. But it may take more time converge. Higher lr can make training faster but also can “oscillate” for convergence.
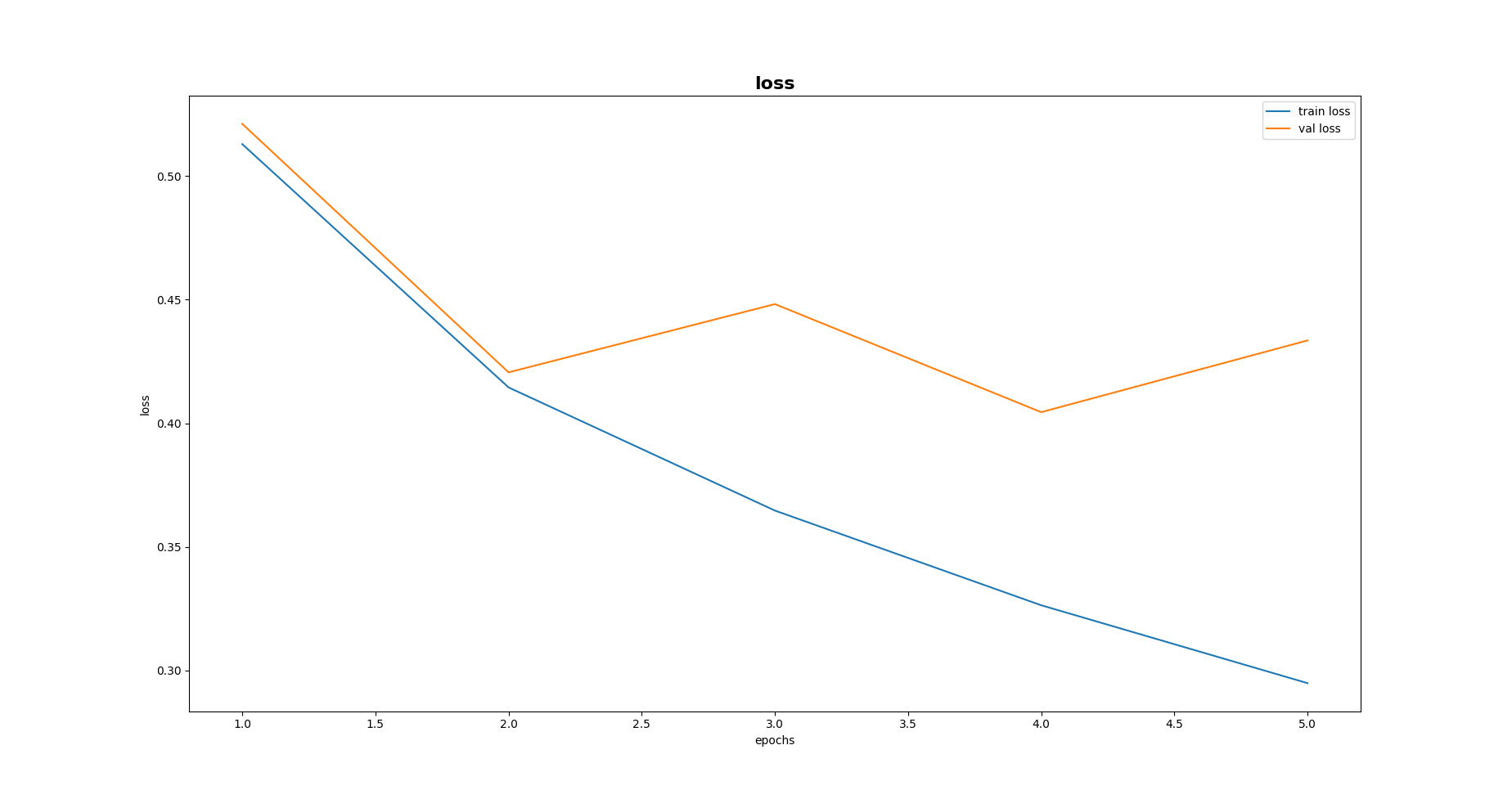
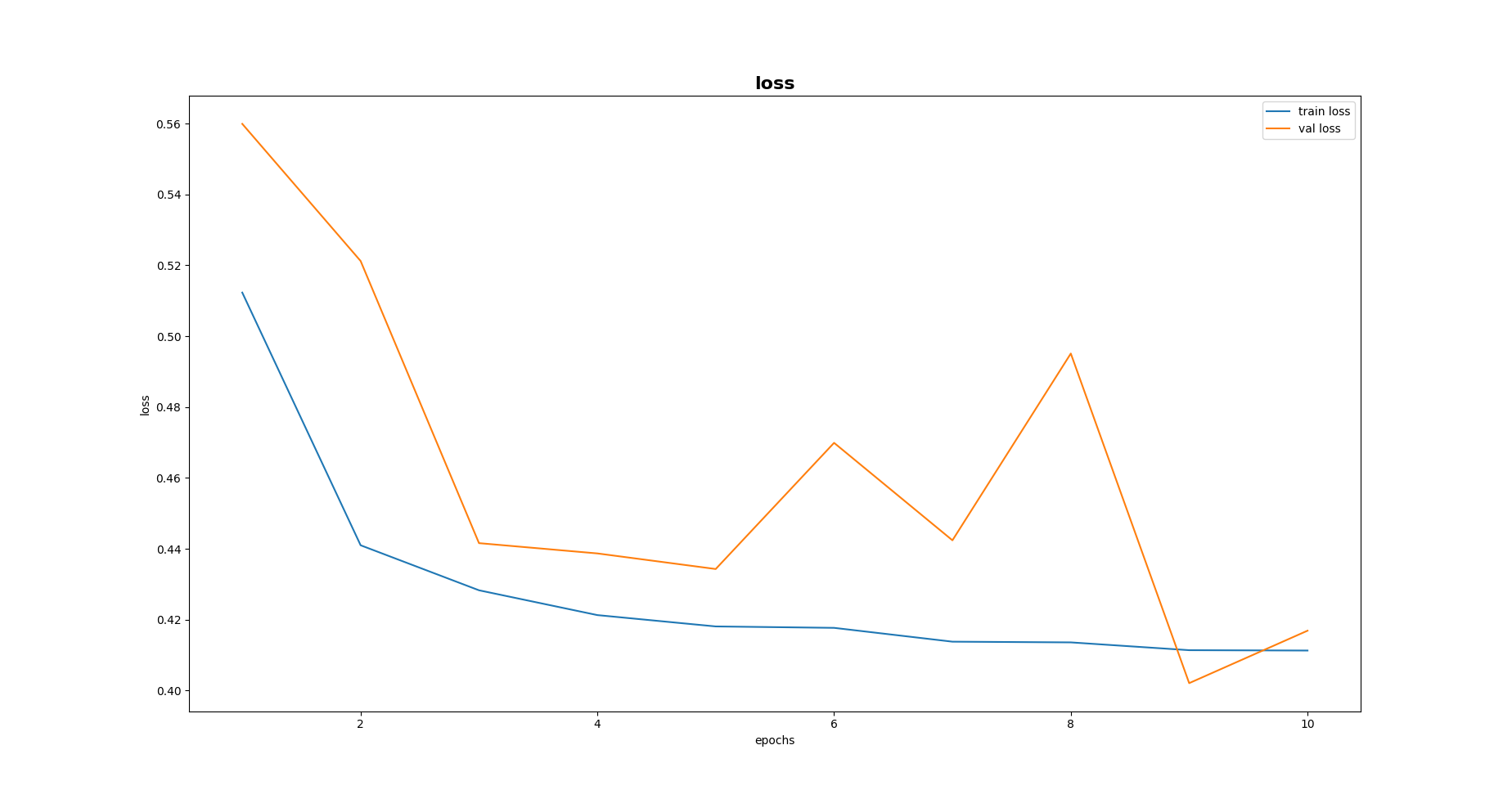
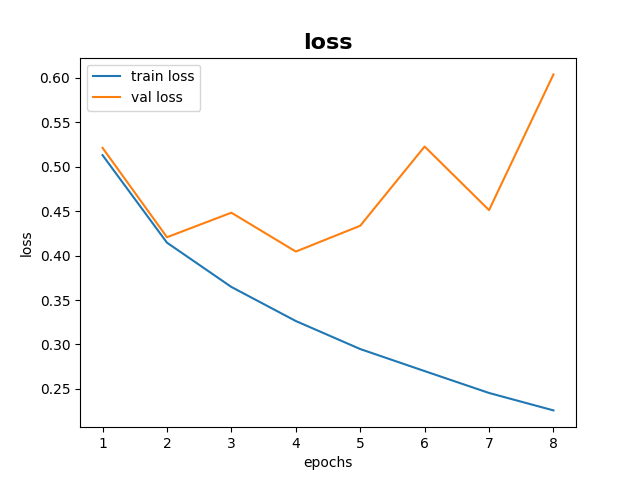
In the case lr = 0.003, the validation loss seems stable, with no significant change. I am not sure if it will improve further from that. In the second case where lr = 0.03, the validation loss goes high and then drops significantly low. It may indicate a bit of overfitting tendency.
I would recommend training for some more epochs for both cases to see if the validation value improves. Also, are you performing weight decay based on epoch or steps?
Can you try with linear weight decaying instead of fixed value i.e. 1st epoch - 0.001, 2nd epoch - 0.0008, 3rd epoch - 0.0004 etc? I guess for lr = 0.003, having a constant weight decay of 0.001 is reducing lr faster than with lr = 0.03.