During the model training, I saved the parameters of the model in the following way:
torch.save(net.state_dict(),path)
After the training, I wanted to get a complete model, so I ran the following Python script:
import torch
import torch.nn as nn
import torchvision.models as models
class MobileNet(nn.Module):
def __init__(self, num_classes, mode, pretrained=True):
super(MobileNet, self).__init__()
assert mode in ["mobilenet_v2", "mobilenet_v3_small", "mobilenet_v3_large"]
self.num_classes = num_classes
self.mode = mode
if mode == "mobilenet_v2":
model = models.mobilenet_v2(pretrained=pretrained)
model.classifier[1] = nn.Linear(in_features=1280, out_features=self.num_classes, bias=True)
elif mode == "mobilenet_v3_small":
model = models.mobilenet_v3_small(pretrained=pretrained)
model.classifier[3] = nn.Linear(in_features=1024, out_features=self.num_classes, bias=True)
elif mode == "mobilenet_v3_large":
model = models.mobilenet_v3_large(pretrained=pretrained)
model.classifier[3] = nn.Linear(in_features=1280, out_features=self.num_classes, bias=True)
self.model = model
def forward(self, x):
x = self.model(x)
return x
if __name__ == "__main__":
our_image = torch.rand(size=(2, 3, 224, 224))
our_model = MobileNet(num_classes=4, mode="mobilenet_v2")
our_model = torch.nn.DataParallel(our_model)
our_model.load_state_dict(torch.load(path))
torch.save(our_model, "./our_model.pt")
However, when I used the complete model I had saved, I got it wrong. The Python script used and the error is as follows:
I was rather puzzled by the error. There is an error indicating that I need to provide the script for building the model, but I have saved the complete model, so I don’t think I need the script for building the model.
Based on the error message it seems as if you’ve saved the model object instead of it’s state_dict.
Are you sure you’ve used torch.save(net.state_dict(),path) and not torch.save(net,path)?
In the latter case, you would need to restore the file structure again to be able to load the model object.
Thank you for your reply. I’m sure I’m using torch.save (net,path). The Python script I use to save the full model is as follows:
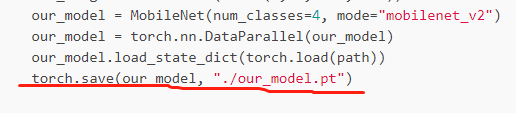
Ah, OK this would explain the error, as this method relies on the same file structure to be able to load the model again.
Check these docs which explain the disadvantage of saving the model object instead of its state_dict:
This save/load process uses the most intuitive syntax and involves the least amount of code. Saving a model in this way will save the entire module using Python’s pickle module. The disadvantage of this approach is that the serialized data is bound to the specific classes and the exact directory structure used when the model is saved. The reason for this is because pickle does not save the model class itself. Rather, it saves a path to the file containing the class, which is used during load time. Because of this, your code can break in various ways when used in other projects or after refactors.
1 Like
Thank you very much. I think I get it. It just saves the path. So what do I do if I want to save a complete model and then use it in other projects?
I think you would need to copy/paste the entire source code with the stored model, but I have to admit not to use this approach as it can easily break and stick to saving the state_dicts instead.
Ok, I see. Thank you very much.
I want to ask you one more question. So if I save the complete model including the structure of the model directly when I train the model, I should be able to save the structure of the model to apply to other projects, instead of just storing parameters and the path of the structure of the model. Or at what point does it save only parameters and model paths?
The common two approaches are mentioned in the linked doc and are basically:
- store the
state_dicts and keep the model source code around. You can refactor the code and as long as the model’s __init__ method creates the same submodules you will be able to load the state_dict into the model. You could change the forward method of the model as the state_dict doesn’t have any knowledge about the forward pass.
- store the model object directly and make sure the project structure is equal in your other setup where you would like to load the model
You could also check the new torch.package module, which might be useful for your use case.
1 Like
Ok, I see. Thank you for your help.
