Hi!
I’m going to build a model like the picture below:
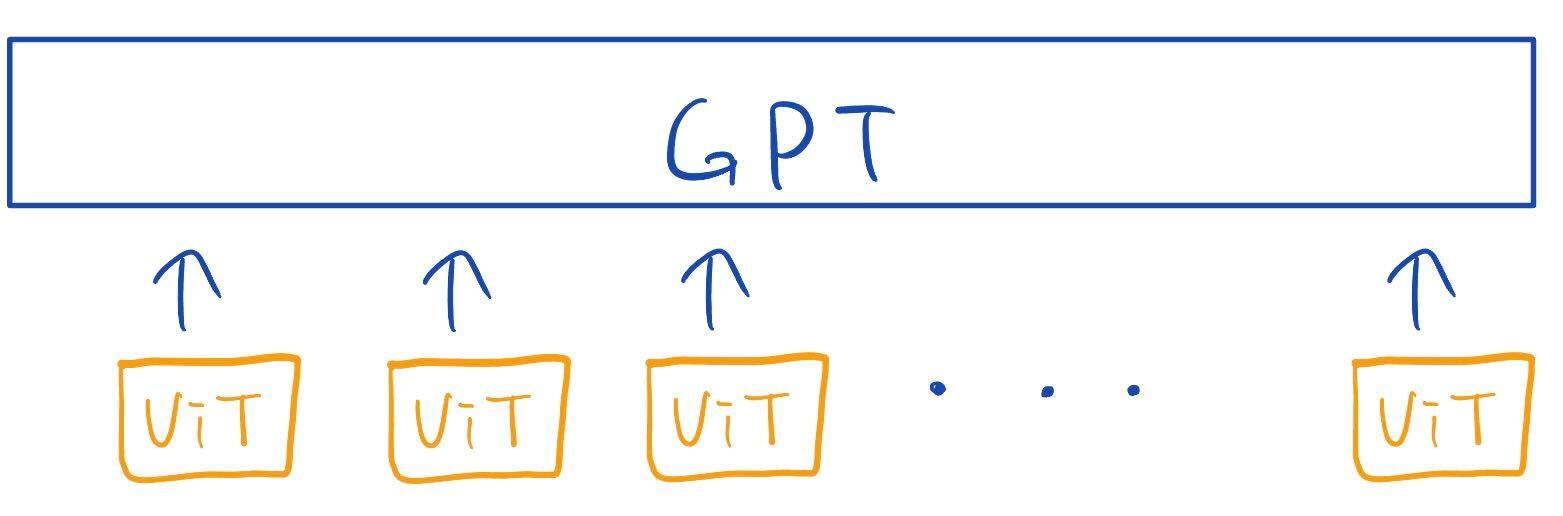
where a vision transformer(ViT) model’s outputs for different pictures are fed into GPT model.
I’m worried about the size of gradient update, and also the training time for this model.
Let’s say that 10 outputs of the ViT are fed into the GPT,
then does this mean that it requires 10 x (size of gradient update of ViT) size GPU memory for training? Or gradient updates are sequentially aggregated on-the-fly, so maybe it requires only 2 x (size of gradient update of ViT)?
Also I guess training this model would require significant amount of time, being very slow…
but I’m not sure whether I’m right or not.
Any guess would be appreciated.
Thanks!