HI!
The artcile:[1712.07628] Improving Generalization Performance by Switching from Adam to SGD
The process

There is my code:
import math
import torch
from torch.optim.optimizer import Optimizer
import numpy as np
class SWATS(Optimizer):
def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-9,
weight_decay=0, amsgrad=False, momentum=0, dampening=0,
weight_decay_a=0, nesterov=False, lambda_k=0 ):
global sgd_on
sgd_on = False
if lr < 0.0:
raise ValueError("Invalid learning rate: {}".format(lr))
if momentum < 0.0:
raise ValueError("Invalid momentum value: {}".format(momentum))
if weight_decay < 0.0:
raise ValueError("Invalid weight_decay value: {}".format(weight_decay))
if weight_decay_a < 0.0:
raise ValueError("Invalid weight_decay_a value: {}".format(weight_decay_a))
if not 0.0 <= betas[0] < 1.0:
raise ValueError("Invalid beta parameter at index 0: {}".format(betas[0]))
if not 0.0 <= betas[1] < 1.0:
raise ValueError("Invalid beta parameter at index 1: {}".format(betas[1]))
defaults = dict(lr=lr, betas=betas, eps=eps,
weight_decay=weight_decay, amsgrad=amsgrad, momentum=momentum,
weight_decay_a=weight_decay_a, nesterov=nesterov, dampening=dampening,
lambda_k=lambda_k)
super(SWATS, self).__init__(params, defaults)
def __setstate__(self, state):
super(SWATS, self).__setstate__(state)
for group in self.param_groups:
group.setdefault('nesterov', False)
group.setdefault('amsgrad', False)
group.setdefault('sgd_on', False)
def step(self, closure=None):
global sgd_on
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
weight_decay = group['weight_decay']
momentum = group['momentum']
dampening = group['dampening']
nesterov = group['nesterov']
for p in group['params']:
if p.grad is None:
continue
if sgd_on:
d_p = p.grad.data
if weight_decay != 0:
d_p.add_(weight_decay, p.data)
if momentum != 0:
param_state = self.state[p]
if 'momentum_buffer' not in param_state:
buf = param_state['momentum_buffer'] = torch.zeros_like(p.data)
buf.mul_(momentum).add_(d_p)
else:
buf = param_state['momentum_buffer']
buf.mul_(momentum).add_(1 - dampening, d_p)
if nesterov:
d_p = d_p.add(momentum, buf)
else:
d_p = buf
p.data.add_(-group['lr'], d_p)
else:
grad = p.grad.data
if grad.is_sparse:
raise RuntimeError('Adam does not support sparse gradients, please consider SparseAdam instead')
amsgrad = group['amsgrad']
state = self.state[p]
# State initialization
if len(state) == 0:
state['step'] = 0
# Exponential moving average of gradient values
state['exp_avg'] = torch.zeros_like(p.data)
# Exponential moving average of squared gradient values
state['exp_avg_sq'] = torch.zeros_like(p.data)
state['p_k'] = torch.zeros_like(p.data)
state['p_k_t'] = torch.zeros_like(p.data)
state['MAD'] = torch.zeros_like(p.data)
state['MAM'] = torch.zeros_like(p.data)
if amsgrad:
# Maintains max of all exp. moving avg. of sq. grad. values
state['max_exp_avg_sq'] = torch.zeros_like(p.data)
exp_avg, exp_avg_sq, p_k, MAD, MAM, p_k_t = state['exp_avg'], state['exp_avg_sq'], state['p_k'], state['MAD'], state['MAM'], state['p_k_t']
if amsgrad:
max_exp_avg_sq = state['max_exp_avg_sq']
beta1, beta2 = group['betas']
state['step'] += 1
# Decay the first and second moment running average coefficient
exp_avg.mul_(beta1).add_(1 - beta1, grad)
exp_avg_sq.mul_(beta2).addcmul_(1 - beta2, grad, grad)
if amsgrad:
# Maintains the maximum of all 2nd moment running avg. till now
torch.max(max_exp_avg_sq, exp_avg_sq, out=max_exp_avg_sq)
# Use the max. for normalizing running avg. of gradient
denom = max_exp_avg_sq.sqrt().add_(group['eps'])
else:
denom = exp_avg_sq.sqrt().add_(group['eps'])
bias_correction1 = 1 - beta1 ** state['step']
bias_correction2 = 1 - beta2 ** state['step']
step_size = group['lr'] * math.sqrt(bias_correction2) / bias_correction1
p_k.addcdiv_(-step_size, exp_avg, denom)
p_k_t = torch.transpose(p_k, 0, 1)
MAD.addcmul_(1.0, p_k_t, grad)
MAM.addcmul_(1.0, p_k_t, p_k)
if MAD != 0.0:
r_k = - MAM / MAD
lambda_k = beta2 * lambda_k + (1 - beta2) * r_k
delta_lr = lambda_k / bias_correction2
if (state['step'] > 1 and delta_lr > 0 and abs(delta_lr - r_k) < group['eps']):
sgd_on = True
group['lr'] = delta_lr
if group['weight_decay_a'] != 0:
decayed_weights = torch.mul(p.data, group['weight_decay_a'])
p.data.addcdiv_(-step_size, exp_avg, denom)
p.data.sub_(decayed_weights)
else:
p.data.addcdiv_(-step_size, exp_avg, denom)
return loss
In this algorithm,we need transpose some tensor,but i don’t konw which dimonsion should be change.
we must ensure that sgd_lr is positive(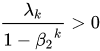 ),so I add an additional condition than that the article has listed
),so I add an additional condition than that the article has listed
Please help me solve it,I will shareit on github after this problem fixed.
Thx!