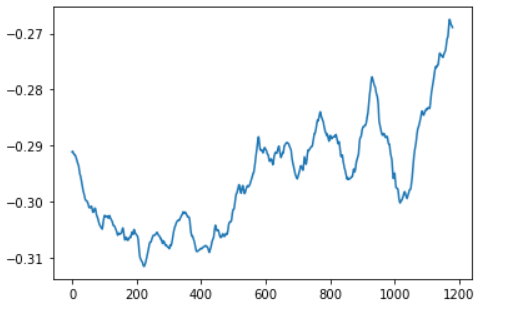
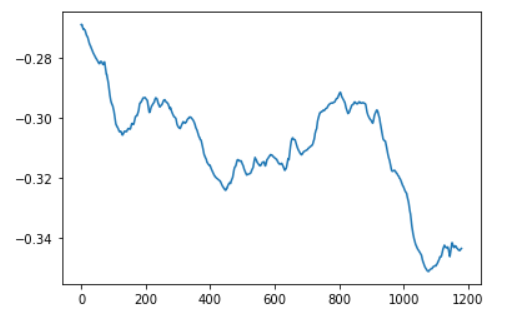
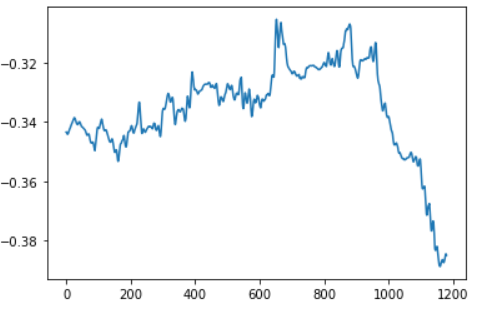
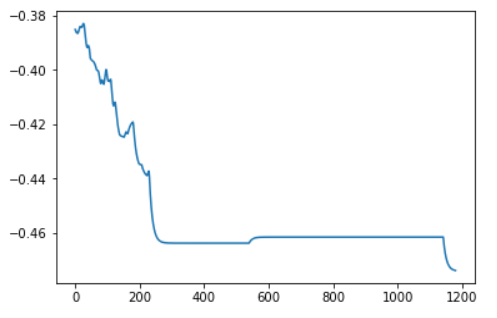
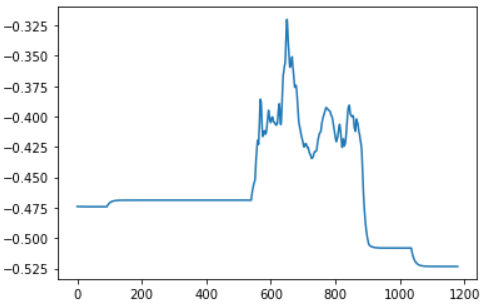
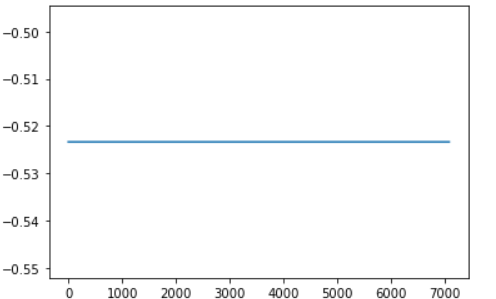
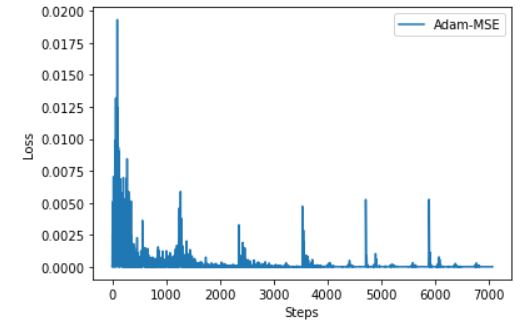
Hi,I have a question about this.Here is the code for my training phase.
I want to get the weight parameters of the first level convolution,
for epoch in range(EPOCH):
NET.train()
torch.manual_seed(3)
print('Epoch:', epoch + 1, 'Training...')
for i, (batch_x, batch_y) in enumerate(loader):
batch_x=Variable(batch_x)
output = NET(batch_x)
loss = lossfunc(output, batch_y)
loss.backward()
optimizer.step()
wc_loss.append(loss.data)
print('Epoch: ', epoch, '| Step: ', i, '| loss: ',wc_loss[i])
for name, param in NET.named_parameters():
if 'network.0.conv1.weight_v' in name:
parm[name]=param.detach().numpy()
b.append(parm['network.0.conv1.weight_v'])
but the result of 【b】is always repeated,same result every updata,like this.(note:The first convolution layer is conv1d,
conv1d(1,3,kernel=3))
[array([[[-11.6726265 , 12.326811 , 12.306071 ]],
[[ 0.4224267 , -0.21204475, -0.07533604]],
[[ 11.559458 , 11.859747 , 12.272797 ]]], dtype=float32),
array([[[-11.6726265 , 12.326811 , 12.306071 ]],
[[ 0.4224267 , -0.21204475, -0.07533604]],
[[ 11.559458 , 11.859747 , 12.272797 ]]], dtype=float32),
array([[[-11.6726265 , 12.326811 , 12.306071 ]],
[[ 0.4224267 , -0.21204475, -0.07533604]],
[[ 11.559458 , 11.859747 , 12.272797 ]]], dtype=float32),
array([[[-11.6726265 , 12.326811 , 12.306071 ]],
[[ 0.4224267 , -0.21204475, -0.07533604]],
[[ 11.559458 , 11.859747 , 12.272797 ]]], dtype=float32),
array([[[-11.6726265 , 12.326811 , 12.306071 ]],
[[ 0.4224267 , -0.21204475, -0.07533604]],
[[ 11.559458 , 11.859747 , 12.272797 ]]], dtype=float32),
array([[[-11.6726265 , 12.326811 , 12.306071 ]],
[[ 0.4224267 , -0.21204475, -0.07533604]],
[[ 11.559458 , 11.859747 , 12.272797 ]]], dtype=float32),
array([[[-11.6726265 , 12.326811 , 12.306071 ]],
[[ 0.4224267 , -0.21204475, -0.07533604]],
[[ 11.559458 , 11.859747 , 12.272797 ]]], dtype=float32),
array([[[-11.6726265 , 12.326811 , 12.306071 ]],
[[ 0.4224267 , -0.21204475, -0.07533604]],
[[ 11.559458 , 11.859747 , 12.272797 ]]], dtype=float32),
array([[[-11.6726265 , 12.326811 , 12.306071 ]],
[[ 0.4224267 , -0.21204475, -0.07533604]],
[[ 11.559458 , 11.859747 , 12.272797 ]]], dtype=float32),
array([[[-11.6726265 , 12.326811 , 12.306071 ]],
[[ 0.4224267 , -0.21204475, -0.07533604]],
[[ 11.559458 , 11.859747 , 12.272797 ]]], dtype=float32),
......
......
However, the value of 【loss】 decreased normally.I don’t know why the value of the weight 【b】 is not updated.