Hey everyone,
I am currently trying to use the Intel FP8 Toolkit and trying to expand it with additional formats. From what I gathered, it builds on the eager PyTorch Quantization method, which uses hooks to modify intermediate layer inputs and outputs.I am interested in static PTQ.
I’ll give a little bit of background, hoping that this will help describing my question precisely:
I really like this approach, as it is easy to comprehend. However, when applying it to transformer models, such as Albert I am facing some issues.
Albert is composed of Attention heads, which can be (simplified) described as:
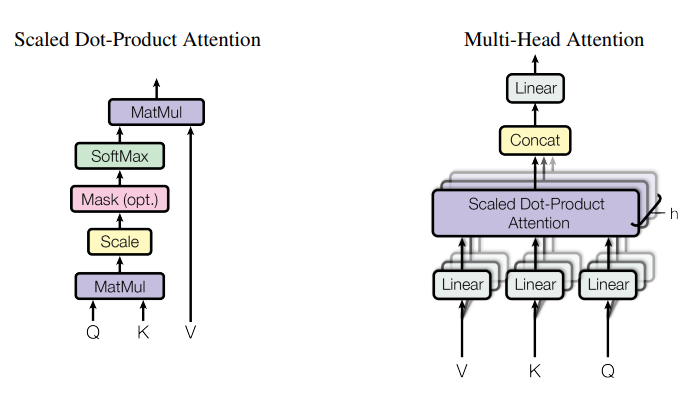
When using the model.named_modules() function on this model, like suggested here this returns (just an excerpt):
List of module names
albert.encoder.albert_layer_groups.0.albert_layers.0.attention
albert.encoder.albert_layer_groups.0.albert_layers.0.attention.query
albert.encoder.albert_layer_groups.0.albert_layers.0.attention.key
albert.encoder.albert_layer_groups.0.albert_layers.0.attention.value
albert.encoder.albert_layer_groups.0.albert_layers.0.attention.attention_dropout
albert.encoder.albert_layer_groups.0.albert_layers.0.attention.output_dropout
albert.encoder.albert_layer_groups.0.albert_layers.0.attention.dense
Code to reprodude
from transformers import AlbertForQuestionAnswering
# get model
model = AlbertForQuestionAnswering.from_pretrained("twmkn9/albert-base-v2-squad2")
# list layer names and layer types
for name, module in model.named_modules():
print(f"{name} | {type(module)}")
Now one could use the names of the linear modules and easily start modifiying the inputs and outputs of for example Q,K and V. But what if I wanted to modify intermediate layers, such as the output of the softmax, to quantize the input of the MatMul?
In the file defining Albert modeling_albert.py we can see the softmax layer, defined as a nn.functional.softmax, which results in it not being created as named_module(). At least that is my understanding.
So, in essence, my question is:
Is there a way to access the input/output of intermediate (unnamed) layers like these? If yes, how should this be done?
Thanks a lot for looking into this!