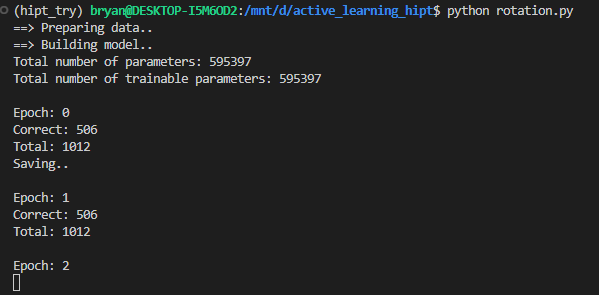
My goal is to predict the rotation of features (90/180/270/360) which makes supervised learning into four classes. The training loss is decreasing, but my accuracy is always 50% over 50 epochs. Here I attached the screenshot and code for the reference
`
print(‘==> Preparing data…’)
train_df_path = Path(cfg.data_dir, cfg.dataset_name, "train.csv")
tune_df_path = Path(cfg.data_dir, cfg.dataset_name, "tune.csv")
train_df = pd.read_csv(train_df_path)
tune_df = pd.read_csv(tune_df_path)
train_set = RotationFeaturesDataset(
train_df,
features_dir,
)
train_sampler = torch.utils.data.RandomSampler(train_set)
train_loader = torch.utils.data.DataLoader(
train_set,
batch_size=cfg.train_batch_size,
sampler=train_sampler,
collate_fn=partial(collate_features, label_type="int")
)
tune_set = RotationFeaturesDataset(
tune_df,
features_dir,
)
tune_sampler = torch.utils.data.SequentialSampler(tune_set)
tune_loader = torch.utils.data.DataLoader(
tune_set,
batch_size=cfg.train_batch_size,
sampler=tune_sampler,
collate_fn=partial(collate_features, label_type="int")
)
# Model
print('==> Building model..')
model = ModelFactory(cfg.level, 4, cfg.model).get_model()
model.relocate()
print(model)
model_params = filter(lambda p: p.requires_grad, model.parameters())
optimizer = OptimizerFactory(
cfg.optim.name, model_params, lr=cfg.optim.lr, weight_decay=cfg.optim.wd
).get_optimizer()
scheduler = SchedulerFactory(optimizer, cfg.optim.lr_scheduler).get_scheduler()
criterion = nn.CrossEntropyLoss()
# Training
for epoch in range(cfg.nepochs):
print('\nEpoch: %d' % epoch)
model.train()
train_loss = 0
train_correct = 0
train_total = 0
for batch_idx, (slide_id, inputs1, inputs2, inputs3, inputs4, targets1, targets2, targets3, targets4) in enumerate(train_loader):
inputs1, inputs2, targets1, targets2 = inputs1.to(device), inputs2.to(device), targets1.to(device), targets2.to(device)
inputs3, inputs4, targets3, targets4 = inputs3.to(device), inputs4.to(device), targets3.to(device), targets4.to(device)
optimizer.zero_grad()
outputs1, embedding1, attention_score1 = model(inputs1)
outputs2, embedding2, attention_score2 = model(inputs2)
outputs3, embedding3, attention_score3 = model(inputs3)
outputs4, embedding4, attention_score4 = model(inputs4)
# # transform targets to one-hot-encoded vectors
# targets1 = torch.nn.functional.one_hot(targets1, num_classes=4).float()
# targets2 = torch.nn.functional.one_hot(targets2, num_classes=4).float()
# targets3 = torch.nn.functional.one_hot(targets3, num_classes=4).float()
# targets4 = torch.nn.functional.one_hot(targets4, num_classes=4).float()
loss1 = criterion(outputs1, targets1)
loss2 = criterion(outputs2, targets2)
loss3 = criterion(outputs3, targets3)
loss4 = criterion(outputs4, targets4)
loss = (loss1+loss2+loss3+loss4)/4.
loss.backward()
optimizer.step()
train_loss += loss.item()
_, predicted1 = outputs1.max(1)
_, predicted2 = outputs2.max(1)
_, predicted3 = outputs3.max(1)
_, predicted4 = outputs4.max(1)
train_total += targets1.size(0)*4
train_correct += predicted1.eq(targets1).sum().item()
train_correct += predicted2.eq(targets2).sum().item()
train_correct += predicted3.eq(targets3).sum().item()
train_correct += predicted4.eq(targets4).sum().item()
# correct += predicted1.eq(targets1.max(1)[1]).sum().item()
# correct += predicted2.eq(targets2.max(1)[1]).sum().item()
# correct += predicted3.eq(targets3.max(1)[1]).sum().item()
# correct += predicted4.eq(targets4.max(1)[1]).sum().item()
model.eval()
test_loss = 0
test_correct = 0
test_total = 0
with torch.no_grad():
for batch_idx, (slide_id, inputs1, inputs2, inputs3, inputs4, targets1, targets2, targets3, targets4) in enumerate(tune_loader):
inputs1, inputs2, targets1, targets2 = inputs1.to(device), inputs2.to(device), targets1.to(device), targets2.to(device)
inputs3, inputs4, targets3, targets4 = inputs3.to(device), inputs4.to(device), targets3.to(device), targets4.to(device)
outputs1, embedding1, attention_score1 = model(inputs1)
outputs2, embedding2, attention_score2 = model(inputs2)
outputs3, embedding3, attention_score3 = model(inputs3)
outputs4, embedding4, attention_score4 = model(inputs4)
# # transform targets to one-hot-encoded vectors
# targets1 = torch.nn.functional.one_hot(targets1, num_classes=4).float()
# targets2 = torch.nn.functional.one_hot(targets2, num_classes=4).float()
# targets3 = torch.nn.functional.one_hot(targets3, num_classes=4).float()
# targets4 = torch.nn.functional.one_hot(targets4, num_classes=4).float()
loss1 = criterion(outputs1, targets1)
loss2 = criterion(outputs2, targets2)
loss3 = criterion(outputs3, targets3)
loss4 = criterion(outputs4, targets4)
loss = (loss1+loss2+loss3+loss4)/4.
test_loss += loss.item()
_, predicted1 = outputs1.max(1)
_, predicted2 = outputs2.max(1)
_, predicted3 = outputs3.max(1)
_, predicted4 = outputs4.max(1)
test_total += targets1.size(0)*4
test_correct += predicted1.eq(targets1).sum().item()
test_correct += predicted2.eq(targets2).sum().item()
test_correct += predicted3.eq(targets3).sum().item()
test_correct += predicted4.eq(targets4).sum().item()
# correct += predicted1.eq(targets1.max(1)[1]).sum().item()
# correct += predicted2.eq(targets2.max(1)[1]).sum().item()
# correct += predicted3.eq(targets3.max(1)[1]).sum().item()
# correct += predicted4.eq(targets4.max(1)[1]).sum().item()
print(f'Correct: {test_correct}')
print(f'Total: {test_total}')
# Save checkpoint.
acc = 100.*test_correct/test_total
print(f'Accuracy: {acc}')
with open('./best_rotation.txt','a') as f:
f.write(str(epoch)+':'+str(acc)+'\n')
if acc > best_acc:
print('Saving..')
state = {
'net': model.state_dict(),
'acc': acc,
'epoch': epoch,
}
# save rotation weights
torch.save(state, Path(checkpoint_dir, 'rotation.pth'))
best_acc = acc
scheduler.step()
`