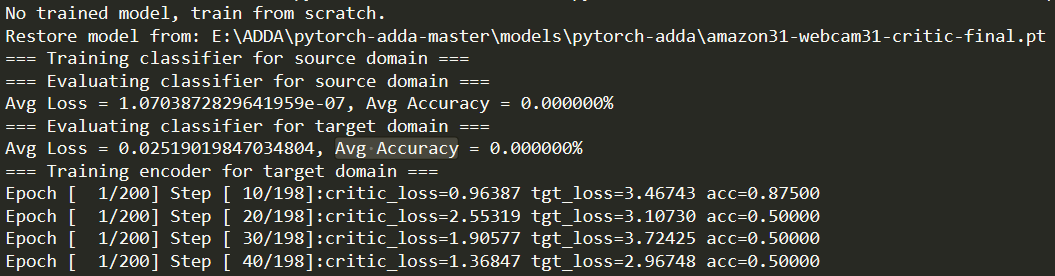
训练和测试的时候这个Avg Accuracy一直是0%,acc有值,这是怎么回事大神们
From Google translate:
When training and testing, this Avg Accuracy is always 0%, acc is worth, what ’s going on?
Could you post the shape of labels and pred_cls, please?
Also, Variables are deprecated since PyTorch 0.4.0 so you can just use tensors in newer versions. ![]()
PS: I’ve edited your title as well so that more users can have a look.
Could you please use a translation service, which would make it easier to support you? 
Print the shapes of all tensors for the accuracy calculation via:
print(pred_cls.shape)
print(...)
so that we can have a look at the calculation.
Also, you can post your code here directly by wrapping it into three backticks ```.
Where should the two prints be added?And can I send the entire code?
No, please don’t send unnecessary code and lets first start with the shape information.
Add the print statements before calculating the accuracy.
...
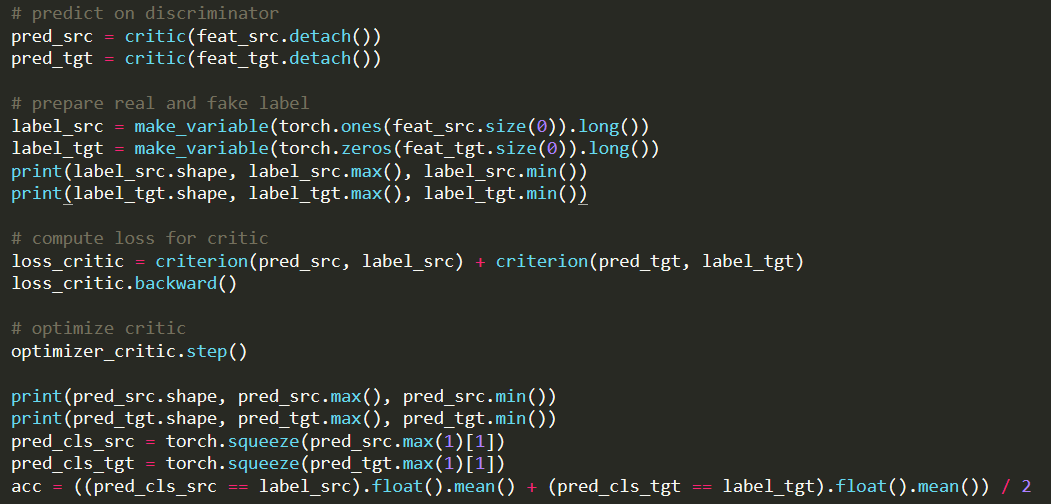
# optimize critic
optimizer_critic.step()
print(pred_src.shape, pred_src.max(), pred_src.min())
print(pred_tgt.shape, pred_tgt.max(), pred_tgt.min())
pred_cls_src = torch.squeeze(pred_src.max(1)[1])
pred_cls_tgt = torch.squeeze(pred_tgt.max(1)[1])
acc = ((pred_cls_src == label_src).float().mean() + (pred_cls_tgt == label_tgt).float().mean()) / 2

What should I do next
Thanks for the output!
Could you do the same for the labels please?
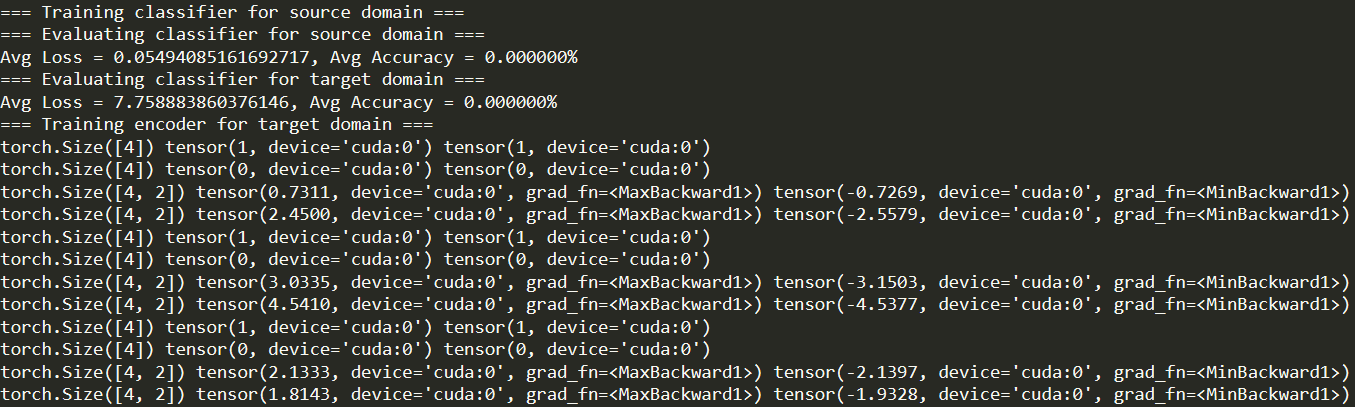
I put print in this position, right? It would be better if you could directly tell me where to add because I am a newbie, please trouble you, thank you!
Based on the shapes the calculation should be correct and it also seems the training loop prints a valid accuracy.
Could you post the code to calculate the validation accuracy directly using three backticks ``` please?
It’s a bit hard to follow your code structure using screenshots.
"""Adversarial adaptation to train target encoder."""
import os
import torch
import torch.optim as optim
from torch import nn
from utils import make_variable
from core.test import eval
def train_tgt(src_encoder, src_classifier, tgt_encoder, critic, src_data_loader, tgt_data_loader, params):
"""Train encoder for target domain."""
####################
# 1. setup network #
####################
# setup criterion and optimizer
criterion = nn.CrossEntropyLoss()
optimizer_tgt = optim.Adam(tgt_encoder.parameters(),
lr=params.tgt_learning_rate,
betas=(params.beta1, params.beta2),
weight_decay=2.5e-5)
optimizer_critic = optim.Adam(critic.parameters(),
lr=params.critic_learning_rate,
betas=(params.beta1, params.beta2),
weight_decay=2.5e-5)
len_data_loader = min(len(src_data_loader), len(tgt_data_loader))
####################
# 2. train network #
####################
for epoch in range(params.num_epochs):
# set train state for Dropout and BN layers
tgt_encoder.train()
critic.train()
# zip source and target data pair
data_zip = enumerate(zip(src_data_loader, tgt_data_loader))
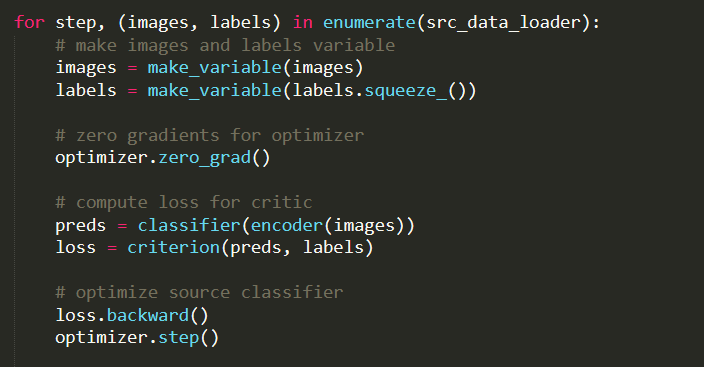
for step, ((images_src, _), (images_tgt, _)) in data_zip:
###########################
# 2.1 train discriminator #
###########################
# make images variable
images_src = make_variable(images_src)
images_tgt = make_variable(images_tgt)
# zero gradients for optimizer
optimizer_critic.zero_grad()
# extract and concat features
feat_src = src_encoder(images_src)
feat_tgt = tgt_encoder(images_tgt)
feat_concat = torch.cat((feat_src, feat_tgt), 0)
# predict on discriminator
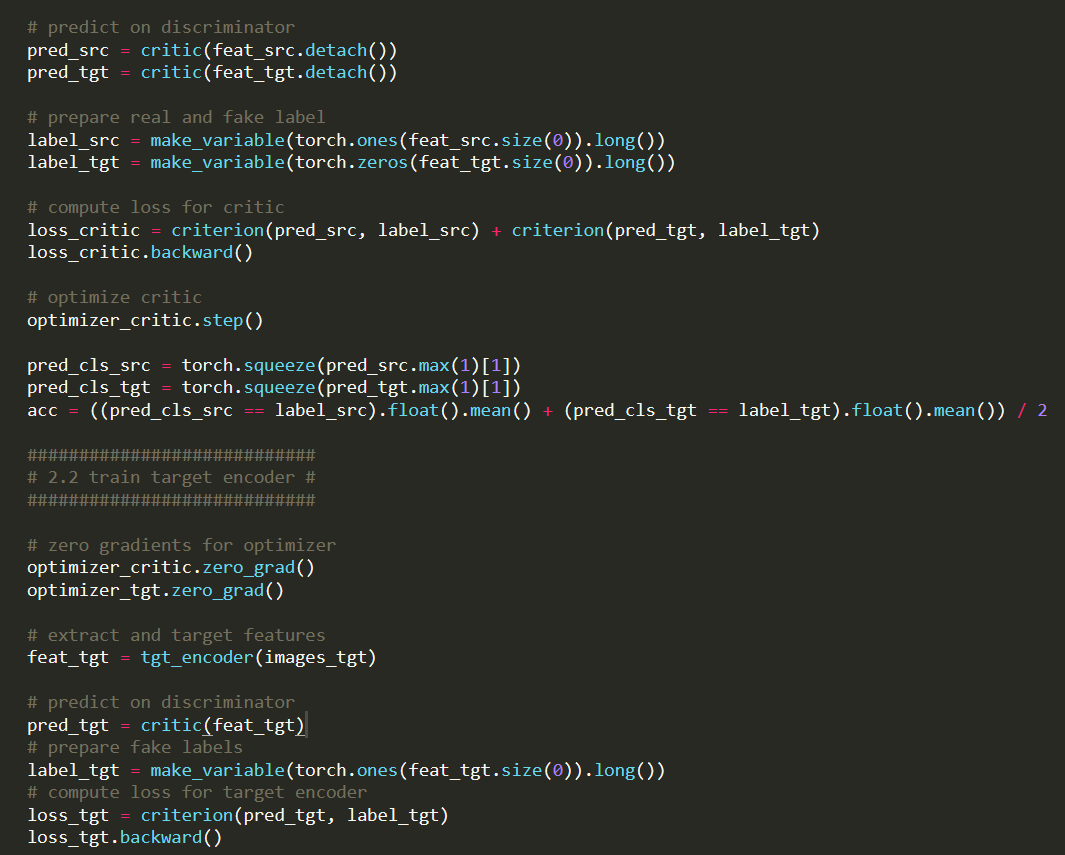
pred_src = critic(feat_src.detach())
pred_tgt = critic(feat_tgt.detach())
# prepare real and fake label
label_src = make_variable(torch.ones(feat_src.size(0)).long())
label_tgt = make_variable(torch.zeros(feat_tgt.size(0)).long())
print(label_src.shape, label_src.max(), label_src.min())
print(label_tgt.shape, label_tgt.max(), label_tgt.min())
# compute loss for critic
loss_critic = criterion(pred_src, label_src) + criterion(pred_tgt, label_tgt)
loss_critic.backward()
# optimize critic
optimizer_critic.step()
print(pred_src.shape, pred_src.max(), pred_src.min())
print(pred_tgt.shape, pred_tgt.max(), pred_tgt.min())
pred_cls_src = torch.squeeze(pred_src.max(1)[1])
pred_cls_tgt = torch.squeeze(pred_tgt.max(1)[1])
acc = ((pred_cls_src == label_src).float().mean() + (pred_cls_tgt == label_tgt).float().mean()) / 2
############################
# 2.2 train target encoder #
############################
# zero gradients for optimizer
optimizer_critic.zero_grad()
optimizer_tgt.zero_grad()
# extract and target features
feat_tgt = tgt_encoder(images_tgt)
# predict on discriminator
pred_tgt = critic(feat_tgt)
# prepare fake labels
label_tgt = make_variable(torch.ones(feat_tgt.size(0)).long())
# compute loss for target encoder
loss_tgt = criterion(pred_tgt, label_tgt)
loss_tgt.backward()
# optimize target encoder
optimizer_tgt.step()
#######################
# 2.3 print step info #
#######################
if ((step + 1) % params.log_step == 0):
print("Epoch [{:3d}/{:3d}] Step [{:3d}/{:3d}]:"
"critic_loss={:.5f} tgt_loss={:.5f} acc={:.5f}"
.format(epoch + 1,
params.num_epochs,
step + 1,
len_data_loader,
loss_critic.item(),
loss_tgt.item(),
acc.item()))
#############################
# 2.4 eval training model #
#############################
if ((epoch + 1) % params.eval_step == 0):
print ("eval model on source data")
eval(tgt_encoder, src_classifier, src_data_loader)
print ("eval model on target data")
eval(tgt_encoder, src_classifier, tgt_data_loader)
#############################
# 2.5 save model parameters #
#############################
if ((epoch + 1) % params.save_step == 0):
torch.save(critic.state_dict(), os.path.join(
params.model_root,
"{}-{}-critic-{}.pt".format(params.src_dataset, params.tgt_dataset, epoch + 1)))
torch.save(tgt_encoder.state_dict(), os.path.join(
params.model_root,
"{}-{}-target-encoder-{}.pt".format(params.src_dataset, params.tgt_dataset, epoch + 1)))
torch.save(critic.state_dict(), os.path.join(
params.model_root,
"{}-{}-critic-final.pt".format(params.src_dataset, params.tgt_dataset)))
torch.save(tgt_encoder.state_dict(), os.path.join(
params.model_root,
"{}-{}-target-encoder-final.pt".format(params.src_dataset, params.tgt_dataset)))
return tgt_encoder"""Test script to classify target data."""
import torch.nn as nn
from utils import make_variable
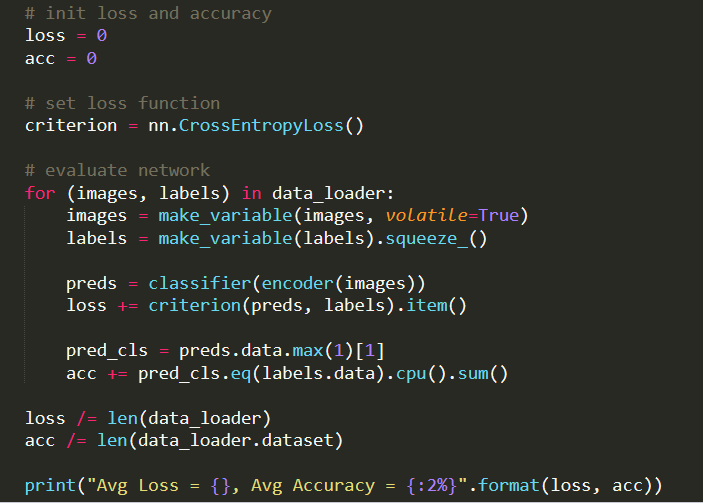
def eval(encoder, classifier, data_loader):
"""Evaluation for target encoder by source classifier on target dataset."""
# set eval state for Dropout and BN layers
encoder.eval()
classifier.eval()
# init loss and accuracy
loss = 0
acc = 0
# set loss function
criterion = nn.CrossEntropyLoss()
# evaluate network
for (images, labels) in data_loader:
images = make_variable(images, volatile=True)
labels = make_variable(labels).squeeze_()
preds = classifier(encoder(images))
loss += criterion(preds, labels).item()
pred_cls = preds.data.max(1)[1]
acc += pred_cls.eq(labels.data).cpu().sum()
loss /= len(data_loader)
acc /= len(data_loader.dataset)
print("Avg Loss = {}, Avg Accuracy = {:2%}".format(loss, acc))The code should still work (besides the deprecated usage of Variable and the .data attribute).
Could you check the pred_cls and labels values in your validation loop?
Just print out the values and check, if the predictions are indeed all wrong, which would yield a zero accuracy.
def eval(encoder, classifier, data_loader):
...
# evaluate network
for (images, labels) in data_loader:
...
print(pred_cls)
print(labels)
print(pred_cls.eq(labels.data).cpu().sum())
acc += pred_cls.eq(labels.data).cpu().sum()
...
Use this code to check your values in the validation loop.
PS: Also, please stick to one user account.
Try to call:
acc = acc.float()
acc /= len(data_loader.dataset)
and check the accuracy again.
It seems acc is an int which should thus result in an integer division when dividing with the length of your dataset.