I implemented an actor critic algorithm, very much inspired from PyTorch’s one. It is doing awesome in CartPole, for instance, getting over 190 in a few hundred iterations. Delighted from this, I prepared for using it in my very own environment in which a robot has to touch a point in space.
In the simplest case:
One single and fixed target
Oriented reward (reward = 1/distance from effector to target)
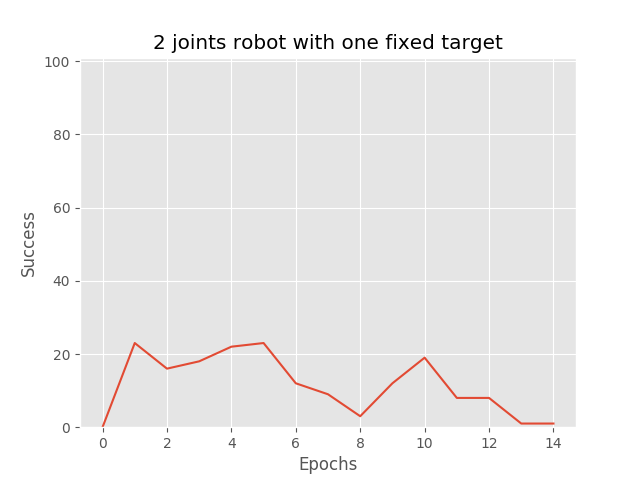
It is not even capable to get over 50%. Furthermore, the performance drops, falling from 20% to 2~3%. It is something that puzzles me. The environment is exactly the same I used for REINFORCE with baseline in which I’m able to get around 100% of success.
Would anyone have an idea about where I could find the flaw ? I must admit, I do not understand. I really thought that given REINFORCE with baseline performances, it would be a piece of cake for AC.
Thanks !
EDIT 29/01/18
Among the various parameters that can cause this implementation to fail, I’m considering that the fact that the critic is not using experience replay → hence, introducing a lot of variance when bootstrapping.
But if it is so, how come it works so well on Cartpole ? Is it because cartpole is so simple that the actor can find it’s way without listening to the critic until the critic finally gets it right ?
I’m going to add experience replay and share my results.
If I understand, an action is a set of joints, then the robot does a trial and receives a reward depending on the distance from the target.
In that case, you are not doing sequential learning. For example, in Cartpole, you have to learn the sequence of actions ‘left left left right right left’. A new action depends on the previous state and action.
Here, when you know the target, you can directly compute a set of angles, wherever was the arm’s initial position. (or maybe the target is moving, so the new state depends on the last position of the target)
After, this does not explain why it fails, as actor critics are solving non-sequential tasks. But it is quite sub-optimal.
Hey ! Thanks for your answer, but I’m not sure I understand want you mean. Are you saying that the reward function is not optimal and it should be based upon the joints angles that would actually reach the target?
it’s not clear what your robot environment’s action space.
With cartpole the action space is discrete action selecting either left and right. (ie. your policy selects either 0 or 1 for left or right action).
What is the action space for your robotic example? I see in the rep the action space is 2*n, where n is number of joints.
Is your policy suppose to output real values (for example degrees of rotation) for each joint? Or is it just suppose to pick 1 joint from the 2*n joints available?
If you’re using the same cartpole implementation for policy, then it will only work for the second case I described above.
If your policy is suppose to output real joint angle values, then you will need a continuous policy distribution (i.e pytorch.distributions.normal) for each k joint angles.
The agent outputs an action, here an integer between 0 and 2*n.
The action indicates the joint number (action/2) and the direction:
left if action%2 == 0 else, right.
The robot then rotates the concerned joint by alpha*direction were alpha is arbitrary and can be modified by user.
My point is that your target new position does not depend on its previous position and neither on your previous action. If it is the case, you are not trying to solve a MDP, but something different, and actor critics may work but is not the optimal solution.
The target is actually fixed. And the robot plays the whole episode. It starts in a configuration and gradually moves according to action. It is also a completely deterministic environment and a MDP.