I’m trying to implement SGD for which I want to penalize the gradient norm resulting in the following loss function. The reason for this is that it has been assosicated with leading to flat minima in deep learning. The loss function looks like this:
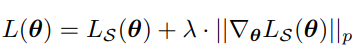
This derives from the paper [1] for which my implementation was inspired by [2].
I started the implementation this for SGD but have the problem that the computed I do not know how I to pass the newly computed parameters to my inplace operator p.data.add_ since the newly computed parameters are not tensors but a list. I want to stack the parameters (not concatenate the parameters) together but since they are of different dimension I do not know how to go about this.
I would be happy for guidance.
[1] https://proceedings.mlr.press/v162/zhao22i/zhao22i.pdf
[2] gnp/optimizer/SGD_class.py at main · zhaoyang-0204/gnp · GitHub
Here is my code:
import numpy as np
import torch
from torch.optim import Optimizer
import optree
from torch.optim.optimizer import Optimizer, required
from typing import Optional, List
class SGD(Optimizer):
@dataclass
class State:
momentum: np.ndarray
def __init__(self,
params,
lr=required,
momentum=0,
dampening=0,
weight_decay=0,
nesterov=False,
maximize=False,
foreach: Optional[bool] = None,
differentiable = False,
grad_norm_clip = None,
):
if lr is not required and lr < 0.0:
raise ValueError("Invalid learning rate: {}".format(lr))
if momentum < 0.0:
raise ValueError("Invalid momentum value: {}".format(momentum))
if weight_decay < 0.0:
raise ValueError("Invalid weight_decay value: {}".format(weight_decay))
defaults = dict(lr=lr, momentum=momentum, dampening=dampening,
weight_decay=weight_decay, nesterov=nesterov,
maximize=maximize, foreach=foreach,
differentiable=differentiable,
grad_norm_clip=grad_norm_clip)
if nesterov and (momentum <= 0 or dampening != 0):
raise ValueError("Nesterov momentum requires a momentum and zero dampening")
super(SGD, self).__init__(params, defaults)
def __setstate__(self, state):
super().__setstate__(state)
for group in self.param_groups:
group.setdefault('nesterov', False)
group.setdefault('maximize', False)
group.setdefault('foreach', None)
group.setdefault('differentiable', False)
group.setdefault('grad_norm_clip', 1.)
group.setdefault('lr', 0.001)
def step(self, closure=None):
loss = None
if closure is not None:
with torch.enable_grad():
loss = closure()
print(self.param_groups[0]['params'])
params_with_grad = []
d_p_list = []
momentum_buffer_list = []
has_sparse_grad = False
for group in self.param_groups:
weight_decay = group['weight_decay']
momentum = group['momentum']
dampening = group['dampening']
nesterov = group['nesterov']
grad_norm_clip = group['grad_norm_clip']
for p in group['params']:
if p.grad is not None:
params_with_grad.append(p)
d_p_list.append(p.grad)
if p.grad.is_sparse:
has_sparse_grad = True
state = self.state[p]
if 'momentum_buffer' not in state:
momentum_buffer_list.append(None)
else:
momentum_buffer_list.append(state['momentum_buffer'])
states = list(self.state.values())
params_flat, treedef = optree.tree_flatten(d_p_list)
states_flat = treedef.flatten_up_to(states)
grads_flat = treedef.flatten_up_to(params_flat)
#gradient clipping
if grad_norm_clip:
grads_l2 = torch.sqrt(sum([torch.dot(p, p) for p in grads_flat]))
grads_factor = min(1.0, grad_norm_clip / grads_l2)
grads_flat = optree.tree_map(lambda param: grads_factor * d_p_list, grads_flat)
out = [
sgd(group, param, state, grad) for param, state, grad
in zip(params_flat, states_flat, grads_flat)
]
new_params_flat, new_states_flat = list(zip(*out)) if out else ((), ())
new_param = optree.tree_unflatten(treedef, new_params_flat)
new_states = optree.tree_unflatten(treedef, new_states_flat)
new_param = [nn.Parameter(param) for param in new_param]
self.state = new_states
p.data.add_(torch.hstack(new_param))
#self.state[p] = new_state
return loss
def sgd(hyper_params, params, state, grad):
momentum_buffer_list = []
d_p = params.clone()
for i, param in enumerate(params):
if hyper_params['weight_decay'] != 0:
param = param.add(param, alpha=hyper_params.weight_decay)
if hyper_params['momentum'] != 0:
buf = momentum_buffer_list[i]
if buf is None:
buf = torch.clone(param).detach()
momentum_buffer_list[i] = buf
else:
buf.mul_(hyper_params['momentum']).add_(param, alpha=1 - hyper_params['dampening'])
if hyper_params['nesterov']:
d_p = param.add(buf, alpha=hyper_params['momentum'])
else:
d_p = buf
#param.add_(d_p, alpha=-hyper_params['lr'])
new_param = param - hyper_params['lr'] * d_p
new_state = SGD.State(new_param)
return new_param, new_state
if __name__ == '__main__':
from torch import nn
model = nn.Linear(10, 20)
optimizer = SGD(model.parameters(), lr=1e-3)
#optimizer.step()
# Create dummy backward pass
m = model(torch.randn(1, 10))
m.mean().backward()
optimizer.step()
#optimizer.load_state_dict(state_dict)
````