Hello. I am trying to do a bit of model surgery to add a GAP layer in a VGG16 net, just before the classifier, after the conv layers. I am replacing the AdaptiveAvgPool2d((7, 7)) normally saved in network.avgpool.
Basically I am doing this:
network = torchvision.models.vgg16(pretrained=False, progress=True)
network.avgpool = torch.nn.AdaptiveAvgPool2d((1, 1))
network.classifier[0] = torch.nn.Linear(512, 4096)
the problem is that this network takes ages to learn, and the testing accuracy is not even that great. I am comparing it with supposedly the same implementation in keras, training it on the same dataset. In keras it trains withtout problem and reaches an accuracy of ~100%, in PyTorch it takes ages, and the accuracy is ~70%, so something is obviously not the same. After having spent long time checking that everything is exactly the same, I am now wondering if my way of adding a GAP layer is wrong. Maybe doing it in that way is breaking some connection in the autograd?
Any help is deeply appreciated, I am totally stuck with this.
Could you explain, what a GAP layer is?
I ran a quick profile on the original VGG16 model and using your modifications and it seems your modifications yield a small speedup (which is expected):
import torch
import torchvision.models as models
import time
model = models.vgg16().cuda()
x = torch.randn(32, 3, 224, 224, device='cuda')
nb_iters = 100
# warmup
for _ in range(10):
out = model(x)
torch.cuda.synchronize()
t0 = time.time()
for _ in range(nb_iters):
out = model(x)
out.backward(torch.ones_like(out))
model.zero_grad()
torch.cuda.synchronize()
t1 = time.time()
print((t1 - t0)/nb_iters)
> 0.1372007703781128
model.avgpool = torch.nn.AdaptiveAvgPool2d((1, 1)).cuda()
model.classifier[0] = torch.nn.Linear(512, 4096).cuda()
torch.cuda.synchronize()
t0 = time.time()
for _ in range(nb_iters):
out = model(x)
out.backward(torch.ones_like(out))
model.zero_grad()
torch.cuda.synchronize()
t1 = time.time()
print((t1 - t0)/nb_iters)
> 0.1326659917831421
You can set torch.backends.cudnn.benchmak = True to profile the kernels and select the fastest one, but I didn’t get a major speedup for this use case.
2 Likes
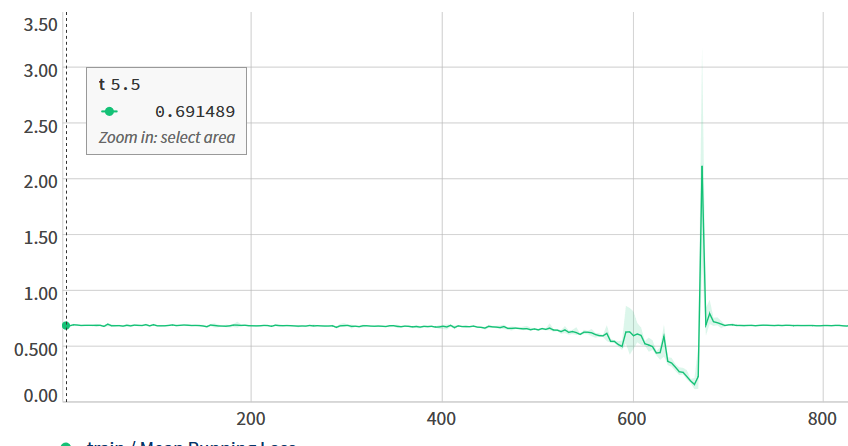
Sorry, GAP = Global Average Pooling. More than timing, I was worried of correctedness of assigning to network.avgpool the new operation. Is this the correct way of doing so? I would assume that, since I would probably get an error if it wasn’t. I am just scraping the bottom of the barrel in order to understand why I get such weird results. For example, the loss goes down (to an accuracy of around 100%) before spiking up to a extremely high value for few iterations:
Yes, it should be the right way. Since you are also changing the first linear layer, you would have a shape mismatch, if you are assigning the new pooling layer to a new attribute (e.g. due to a typo).
Are you using an adaptive optimizer? If not, could you try to lower the learning rate before the spike?
Sometimes when the learning rate is too high, your model might hit these high loss peaks.
1 Like
I am using a standard SGD with no adaptive optimizer. I will try to lower the learning rate, thanks!
I just wanted to report about the spikes and the slow learning. I have tried with a learning rate of 0.0001 (compared to the 0.001 I had before) and it didn’t help at all. It took REALLY LONG to learn (compared to SGD 0.0001), it got rid of the spikes, but accuracy at test time was really slow.
I then changed it to Adam optimizer: accuracy at test time is still high, and it takes 1/10th of the time to train!